Data Layer
Im Zusammenhang mit Tag Management und Web Analytics fällt oft der Begriff Data Layer.
Ein Data Layer ist das fundamentale Element in einem ambitionierten Analytics Setup, da alle Tracking-Regeln auf ihn aufbauen.
In der Web-Analytics Branche wird der Data Layer daher oft wie eine unverhandelbare Voraussetzung für ein Analytics Setup behandelt. Es gibt jedoch auch Situationen, in denen ein Data Layer unnötig ist.
In den folgenden Zeilen möchte ich daher erklären, was ein Data Layer ist, welches Problem er löst und die Unterschiede zwischen einem Google Tag Manager Data Layer und dem Adobe Data Layer.
Danach betrachten wir, die Data Layer Implementierung und durchlaufen schrittweise das Design, dann die Implementierung und das Debugging für die gängigen Tag Management Systeme.
Was ist ein Data Layer?
Ein Data Layer ist eine Datenstruktur die relevante Informationen in Key-Value Pairs zur Nutzung mit z.B. Tag Management Systemen bereitstellt.
Ein Data Layer ist im globalen JavaScript Scope der Webseite als Array oder Object verfügbar und hält Daten in strukturierter Form für andere Programme verfügar.
Der Nutzen eines Data Layers liegt in einem programmatisch einfachem Zugang zu relevanten Daten während eines Webseitenaufrufs.
Der Data Layer macht Daten zentral abrufbar und ist Ausgangspunkt für eine datenbasierte Tracking- und Analytics-Logik in Tag Management Systemen.
window.dataLayer = window.dataLayer || [{"pageCategory": "category page","pageName": "sneaker overview","language": "en-US",}];
Mit einem Data Layer wird also ein zentraler Datenspeicher erschaffen, um Daten aus verschiedenen Quellen zu sammeln und zu beobachten.
Dieser Ansatz (“single point of truth”) ermöglicht, dass nur eine Datenquelle für die Regelausführung beobachtet werden muss und kein Zweifel über die aktuellen Werten einer Variable aufkommt.
Der Data Layer wird bei jedem Seitenaufruf neu erstellt und mit den jeweiligen Daten der neu aufgerufenen Seite ausgestattet.
Hinweis: Bei Single-Page-Applications (SPAs) entsteht kein neuer Ladevorgang während der Seitennavigation. Deshalb wird ein Data Layer für Single-Page-Applications anders konfiguriert, als für klassische Webseiten mit Ladevorgängen.
Die Daten im Data Layer repräsentieren Merkmale und Ereignisse der jeweiligen Unterseite. Jedes Merkmal wird durch ein Schlüsselwort und einen zugeteilten Wert beschrieben (Key-Value-Pairs).
window.dataLayer = window.dataLayer || [{"pageCategory": "category page", //Kategorie"pageName": "sneaker overview", //Name"language": "en-US", //Sprache}];
Das Ziel dabei ist, diese Daten im TMS zugänglich zu machen, damit sie mit anderen Plattformen, wie z.B. Google Analytics oder Facebook Ads, genutzt werden können.
Um diese Integration zu erreichen, hält das TMS Referenzen zu den Schlüsselwörtern und kann dann regelbasiert Tags ausführen, wenn die Schlüsselwörter einen bestimmten Wert annehmen oder sich ändern.
Beispiel: Ein Besucher zoomt in ein Produktbild und ein Ereignis “Produkt Zoom” wird zu Google Analytics gesendet. Das Ereignis alleine ist nicht sehr aufschlussreich. Daher sendet man gleichzeitig andere Daten, wie den Produktnamen, die Produktkategorie und den Preis. Mit diesen zusätzlichen Daten kann das Ereignis in einem besseren Kontext analysiert werden.
Man könnte so z.B. überprüfen, ob einige Produktkategorien eine vergleichsweise hohe Anzahl an Produkt-Zoom-Ereignissen aufweisen, um anschließend zusätzliche Produktbilder in diesen Kategorien zugänglich zu machen.
Die Quintessenz meiner Erklärung des Data Layers ist, dass man Schlüsselwörtern Werte zuordnet und diese Werte zentral speichert.
Die Werte sind oft wichtige Merkmale oder Inhaltskategorien, die entweder für die Datenanalyse oder für das Erstellen einer Tracking Logik wichtig sind.
Um besser zu verstehen was ein Data Layer ist, kann man sich als bildliche Vereinfachung eine Excel-Tabelle vorstellen. Die Tabelle hält die für die Seite wichtigen Schlüsselwörter in den Spaltenüberschriften mit den jeweils zugeordneten Werten:

Welches Problem löst ein Data Layer?
Während ein Besucher mit der Webseite interagiert, werden mehrere Ereignisse ausgeführt: Klicks auf Buttons, das Ausfüllen von Kontaktformularen oder das Ansehen von Videos und Bildern.
Insofern die Ereignisse Rückschlüsse auf das User Engagement ermöglichen, werden sie getrackt und es werden zusätzliche Daten mitgesendet, die z.B. die Besucher, die Session oder das Ereignis und das genutzte HTML-Element näher beschreiben.
Und hier liegt der Knackpunkt: Die zusätzlichen Daten kommen häufig aus verschiedenen Datenquellen z.B. vom Frontend, der Datenbank oder von einem API.
Um zu verstehen, welche Probleme ein Data Layer löst, müssen wir erst wissen, welche Probleme entstehen, wenn wir ohne Data Layer versuchen Daten aus diesen Datenquellen zu gewinnen.
Lasst uns also mit Hilfe eines Beispiels die Beschaffung der Daten aus verschiedenen Datenquellen (Frontend, Datenbank und API) durchdenken:
Beispiel: Der Besucher kauft ein Produkt auf der Webseite. Für den Produktkauf könnten folgende Daten von Interesse sein:
- Produktname
- Produktpreis
- Produktgröße
- Produktkategorie
- Produktfarbe
- Wert des Einkaufskorbs
- Marke
- Erstkauf
- Kundengruppe
- Kundenrabatt
- Geschlecht
- Land
Für gewöhnlich ist eine Transaktion abgeschlossen, sobald man auf einer Danke-Seite landet, die die Details der Transaktion auflistet.
Frontend: Um alle Daten mit der Transaktion zu verknüpfen, könnten wir die Produktdaten, den Wert des Einkaufskorbs und die Marke vermeintlich von der Danke-Seite scrapen.
Das Hauptproblem beim Scrapen aus dem Frontend ist, dass die benötigten Daten auf der Seite vorhanden sein müssen. Denn das ist in der Realität eher selten der Fall.
Außerdem ist es üblich, Ereignisse weitestgehend mit den selben Dimensionen zu tracken. Dadurch kann man sie später einfach vergleichen.
Um also nicht auf allen Seiten künstlich die Daten in den Inhalt integrieren zu müssen, nutzt man einen Data Layer. Er macht die Daten zugänglich, ohne dass sie auf der Seite sichtbar sein müssen.
Eine anderer Nachteil beim direkten Scrapen vom Frontend ist, das es nicht robust genug ist. Sobald Code-Änderungen implementiert werden und sich dadurch die Struktur der relevanten HTML-Elemente verändert, funktioniert es nicht mehr und muss neu aufgesetzt werden.
Datenbank: Bei den Kundendaten (Kundengruppe, Rabatt, Geschlecht, Erstkauf) wird es komplizierter: Kundendaten müssten entweder zusammen mit der Serverantwort kommen oder von einem separaten API.
Bei der Abfrage durch einen API ergibt sich jedoch ein Sicherheitsproblem, da die Authentifizierungsdaten für den API nicht im Browser hantiert werden sollten. Geübte Nutzer könnten sonst leicht Zugang zu Authentifizierungsdaten bekommen.
Die Daten standardmäßig ohne Aufforderung mit der Serverantwort mitzusenden ist die beste Lösung, da so der Authentifizierungsstatus der Webseite genutzt werden kann: Ist man als Nutzer eingeloggt, werden die Daten an den Browser mitgesendet, andernfalls nicht.
API: Geografische Daten, wie z.B. das Land des Besuchers, könnten über externe Dienste mittels eines APIs abgerufen werden.
Nachteile sind hier, genau wie beim Zugang zum Datenbank API, dass das Passwort oder der Zugangsschlüssel zum API im Browser hantiert werden müsste und somit für geübte Nutzer im lokalen Code des Browsers zugänglich wären.
Ein anderer Nachteil ist, dass man die Antwort des APIs abwarten muss. Wenn der User in der Zwischenzeit zu einer anderen Seite navigiert, könnte ein Ereignis verloren gehen.
Jetzt wo wir die einzelnen Herausforderungen beim Einsammeln von Daten ohne Data Layer verstehen, können wir die Vorteile des Data Layers erkennen:
Vorteile eines Data Layers
- Daten sind verfügbar unabhängig davon was sichtbar auf der Seite ist
- robustes Datensammeln
- sicherer Gebrauch sensibler Daten
- Pobleme mit asynchroner Datenabfrage werden minimiert
Warum du (wahrscheinlich) einen Data Layer brauchst
Durch die Erschaffung eines Data Layers wird beim Seitenaufbau jeder Unterseite ein JavaScript-Objekt mit den benötigten Daten im globalen Scope des Browsers zugänglich gemacht.
Die Daten können aus der Datenbank, dem Frontend oder von APIs stammen, d.h. die Datenerfassung verläuft insgesamt sicherer, verlässlicher und Probleme mit sich verändernder HTML-Struktur werden minimiert.
Zusätzlich wird ein Analytics Setup unabhängig davon das Daten auf den Unterseiten vorhanden sein müssen. Daten aus der Datenbank können mit einem Data Layer auf allen Unterseitein einer Webseite zugänglich gemacht werden, ohne dass sie zu sehen sein müssen.
Ich rate grundsätzlich dazu einen Data Layer zu implementieren, da die Vorteile in puncto Datenqualität, Verlässlichkeit und die damit zusammenhängenden Zeitersparnisse mittelfristig, den höheren Implementierungsaufwand rechtfertigen.
Das höhere Ziel von Web-Analytics ist letztlich datenbasierte, unternehmerische Entscheidungen zu treffen. Datenqualität sollte daher Priorität haben.
Lasst uns einen Blick auf die verschiedenen Anbieter von Tag Management Systemen und die damit verbundenen Implikationen auf den Data Layer werfen. Danach schauen wir uns an, wie man einen Data Layer plant, designt und letztlich implementiert.
Data Layer für Adobe Analytics, DTM, Launch und Tealium
Data Layer können sich in Ihrer Struktur unterscheiden. Grundsätzlich unterscheidet man zwischen Data Layern mit Objekt-basierter oder Array-basierter Struktur.
Gemäß der Definition eines Data Layers vom World Wide Web Consortium (W3C), folgt die Data Layer Struktur der Struktur eines JavaScript Objektes und wird inoffiziell CEDDL (Customer Experience Digital Data Layer) abgekürzt.
In dem Data Layer Objekt können beliebig viele weitere Objekte oder auch Arrays vernestet werden:
window.digitalData = {pageName: "sneaker overview",destinationPath: "/en/sneakers",breadCrumbs: ["home","sneakers"],publishDate: "2020-07-01",language: "en-US"};
Adobe Analytics bzw. Adobe Launch und Tealium iQ folgen der CEDDL Struktur. Im obigen Beispiel werden die Daten in einem Objekt digitalData gespeichert. Der Name ist jedoch nicht standardisiert und kann beliebig gewählt werden, muss jedoch im Tag Management System angegeben werden.
Die Änderung der Werte kann abhängig vom TMS verschieden konfiguriert werden. Die einfachste Lösung ist jedoch die Werte zu überschreiben:
window.digitalData.language = "de-DE";
Der zentrale Gedanke bei Objekt-basierten Data Layern ist, dass der Data Layer einmal beim Laden der Seite aufgebaut wird, jedoch nicht laufend während der User Journey verändert wird. Die Daten sind also in der Regel statisch.
Ereignisse werden nicht im Data Layer erfasst, sondern mit separaten Tracking Codes direkt zu z.B. Adobe Analytics geschickt. Bei der Code-Ausführung werden andere relevante Daten vom Data Layer abgegriffen und mitgeschickt. Der Data Layer wird jedoch nicht verändert.
//Ereignis inkl. gewählter Farbe_satellite.setVar("sneaker color", "black");_satellite.track("select color");
Adobe Launch mit Array-basiertem Data Layer nutzen
Adobe launch kann verhältnismäßig einfach auch mit einem Array-basierten Data layer genutzt werden.
Die Adobe Launch Extension Data Layer Manager macht es möglich. Hier Links zu weiterführenden Ressourcen:
- Jim Gordon’s Demo für den Gebrauch von Data Layer Manager mit Adobe Launch
- Data Layer Manager Extension mit Dokumentation
Google Tag Manager Data Layer
Der Data Layer für Google Tag Manager, Matomo und Piwik Pro ist ein Array-basierter Data Layer und wird inoffiziell EDDL (Event Driven Data Layer) abgekürzt.
Daten werden zwar auch in Objekten hantiert, jedoch ist die GTM Data Layer Struktur ein Array mit Objekten.
window.dataLayer = window.dataLayer || [{"pageCategory": "category page","pageName": "sneaker overview","language": "en-US",}];
Bei einem Array-basierten Data Layer verläuft die Tracking-Logik anders: Es werden neue Objekte in das Array mittels dataLayer.push() gesendet. Die Änderung des Data Layers kann dann eine Trackingregel für ein Ereignis auslösen.
Der fundamentale Unterschied zu Objekt-basierten Data Layern ist also das Änderungen durch Events gekennzeichnet werden und auf diese Änderungen die Regeln im Tag Management System aufgebaut sind.
Zusätzlich haben wir im Vergleich zum obigen Beispiel eine Abhängigkeit weniger, da zum Tracken keine andere Bibliothek wie _sattelite notwendig ist.
Außerdem verändern sich die Daten in einem Google Tag Manager Data Layer während der User Journey, da der Nutzer durch Interaktionen Ereignisse auslöst, die die Daten dynamisch ändern.
Ein Array-basierter Data Layer ist also Ausgangspunkt für das Event-Tracking und hantiert Daten flexibler, während ein Objekt-basierter Data Layer mehr als statischer Datenspeicher dient.
Durch diese Flexibilität, wird Array-basierten Data Layern eine bessere Eignung für das Tracking von Single-Page-Applikationen nachgesagt.
Man kann SPAs jedoch auch mit Objekt-basierten Data Layern tracken, man muss nur etwas mehr benutzerdefinierten Code schreiben und ggf. entstehen ein paar Grenzfälle, die es zu lösen gilt.
Wenn man jedoch am Anfang eines Tracking Projektes für eine Single-Page-Application steht und frei wählen kann, würde ich ein TMS mit einem Array-basierten Data Layer bevorzugen.
Einen bestehenden Adobe Analytics Data Layer widerum auf einen GTM Data Layer umzustellen, ist unnötig.
Content Management Systeme inklusive Data Layer
Wer eine Wordpress Webseite nutzt und daran interessiert ist einen Data Layer zu implementieren, kann sich freuen: Wordpress Nutzer können mit diesem Plugin Google Tag Manager und gleichzeitig einen vorkonfigurierten Data Layer implementieren.
Danach verfügbare Daten im Data Layer sind z.B. Kategorien, Autorennamen und Publizierungsdaten, sowie Suchwörter der Suchfunktion.
Die Daten können in den Einstellungen einfach per checkbox gewählt werden. Außerdem bietet das Plugin vorkonfigurierte Data Layer Events für gängige Kontaktformulare.
Man bekommt sehr viel Funktionalität ohne viel Aufwand. Zusätzliche Ereignisse müssen jedoch manuell zum Code hinzugefügt werden.
Wer einen Onlineshop mit WooCommerce für Wordpress betreibt, kann außerdem mit demselben Plugin einen classic E-Commerce und einen enhanced E-Commerce Data Layer erstellen, was ziemlich beeindruckend ist.
Wer Tealium mit Wordpress nutzen möchte, findet ein ähnliches Plugin für Tealium.
Für Drupal gibt es das Data Layer Plugin.
Wix und Squarespace Nutzer können Google Tag Manager über die Platform Tools installieren, aber müssen den Data Layer mittels JavaScript selber implementieren.
Data Layer implementieren
Wie implementiert man einen Data Layer selber? - Da die Planung und Implementierung eines Data Layers sich über die Bereiche Web Analytics und Backend- & Frontend-Programmierung erstreckt, verläuft sie in der Regel mit einem Webbüro bzw. Programmierer in Zusammenarbeit mit einem Analytics Consultant.
Der Analytics Consultant brieft die Agentur oder den Programmierer, steuert das Projekt und validiert schließlich die Implementierung. Nach der Abnahme der Implementierung konfiguriert er das Tag Management System und das Analytics Tool.
Wer neugierig ist und ein bisschen JavaScript beherrscht, kann versuchen einen Data Layer selbst zu implementieren. Im Folgenden also ein Guide zum Data Layer selber machen.
Die Implementierung eines Data Layers durchläuft drei Phasen:
1. Data Layer Design
In der Designphase wird geplant, welche Daten der Data Layer beinhalten sollte.
Alle Merkmale von Besuchern, Sitzungen, Seiten, Produkten oder Ereignissen die aufschlussreich für die Ziele der Datenanalyse sind, sind relevant und sollten für die Architektur des Data Layers bedacht werden.
Um zu entscheiden welche Daten im Data Layer gehalten werden sollten, ist es hilfreich zu überlegen, welche unternehmerischen Fragen es zu beantworten gilt. Mit dem Endresultat im Kopf, kann man danach alle möglichen Daten der Webseite ein- oder ausschließen.
Abschließend sollte man die wichtigsten Dimensionen per Datenpunkt berücksichtigen und die notwendige Struktur beim Datensammeln von der finalen Datenanalyse aus rekonstruieren.
Beispiel: Eine Sprachschule mit einer mehrsprachigen Wordpress Webseite möchte die Muttersprache, sowie das Sprachinteresse definieren, um ggf. eine Werbekampagne mit Facebook Ads zu starten, welche auf eine Zielgruppe mit ähnlichen Charakteristiken abziehlt.
Folglich müssen für alle Seitentypen (z.B. Homepage, Kursseiten, Über Uns, Kontakt, Neuigkeiten) die relevanten Daten für die Datenanalyse definiert werden. Der Einfachheit halber, konzentrieren wir uns im unteren Beispiel auf die Homepage und die Kursseiten:
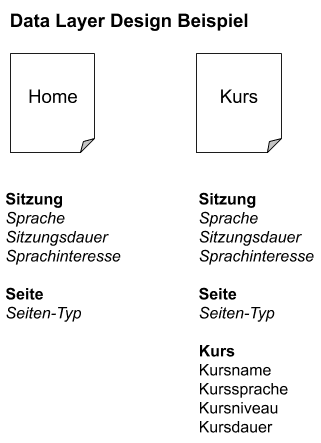
Beispiel: Array-basierter Google Tag Manager Data Layer für die Sprachschule
window.dataLayer = window.dataLayer || [{"language": "de", //Sprachcode für gewählte Sprache"sessionDuration": "182", //Dauer der Sitzung in Sekunden"languageIntent": "es", //Meistbesuchte Kurssprache"pageType": "course page","courseName": "Spanisch A1 - Anfänger","courseLang": "es","courseLevel": "a1","courseDuration": "6" //Dauer in Wochen}];
Beispiel: Webseite einer Sprachschule mit Objekt-basiertem Data Layer für Adobe Launch
window.digitalData = window.digitalData || {"language": "de", //Sprachcode für gewählte Sprache"sessionDuration": 182, //Dauer der Sitzung in Sekunden"languageIntent": "es", //Meistbesuchte Kurssprache"pageType": "course page","courseName": "Spanisch A1 - Anfänger","courseLang": "es","courseLevel": "a1","courseDuration": 6 //Dauer in Wochen};
2. Implementierung
Um den Data Layer zu implementieren, muss auf jeder Unterseite ein Data Layer mit den jeweiligen Daten initiiert werden.
Die obigen Beispiele zeigen den finalen, errechneten Data Layer (Data Layer im computed state).
Bei der Implementierung müssen die Daten jedoch aus den Datenquellen erhoben werden, damit sie im letztlich im Data Layer erscheinen. Der eigentliche Quelltext sieht also anders aus.
Um ein realistisches Beispiel geben zu können, gehe ich von folgenden Prämissen für die Datenerhebung aus:
- Sitzungsdauer und das Sprachinteresse werden durch ein selbst erstelltes JavaScript im Speicher des Browsers festgehalten.
- Seitensprache, Seitentyp, sowie Kursdaten werden im Backend bestimmt und mit der Serverantwort in den Seitentemplates zugänglich gemacht.
Der Quelltext im Backend sieht dann gemäß der obigen Prämissen in etwa wie folgt aus:
window.dataLayer = window.dataLayer || [{"language": <?php echo wpb_getpagedata("lang"); ?>,"sessionDuration": window.localStorage.sessionDuration,"languageIntent": window.localStorage.languageIntent"pageType": <?php echo wpb_getpagedata("type"); ?>,"courseName": <?php echo wpb_getcoursedata("name"); ?>,"courseSprache": <?php echo wpb_getcoursedata("lang"); ?>,"courseLevel": <?php echo wpb_getcoursedata("level"); ?>,"courseDuration": <?php echo wpb_getcoursedata("duration"); ?>,}];
Event-Tracking mit Data Layer Push
Bei Array-basierten Data Layern für GTM, Matomo oder Piwik Pro werden Daten mittels dataLayer.push() mit einem Event dem Data Layer hinzugefügt.
window.dataLayer.push({"event": "course-booking","startWeek": "24"});
Event ist ein spezielles Schlüsselwort in Google Tag Manager und kann als benutzerdefiniertes Ereignis in GTM referiert werden.
Das Tag Management System überwacht den Data Layer und führt eine beliebige Aktion aus, sobald ein bestimmter Event mittels Data Layer Push hinzugefügt wird.
Sobald der Event in den Data Layer geschickt wird, übernimmt die Logik des TMS und sendet z.B. ein Ereignis an Google Analytics.
Alle relevanten Daten, um den Event näher zu beschreiben (Name, Sprache, Niveau und Dauer) sind im Data Layer verfügbar - z.B. auch die Startwoche, die mit dem Event mitgesendet wurde.
Derselbe Event würde bei einem Objekt-basierten Data Layer nicht im Data Layer, sondern von einem eigenständigen Code geschickt werden.
Mit Adobe Launch würde das Code-Beispiel für den Event wie folgt aussehen:
_satellite.setVar("startWeek", 24);_satellite.track("course-booking");
Positionierung im Quelltext
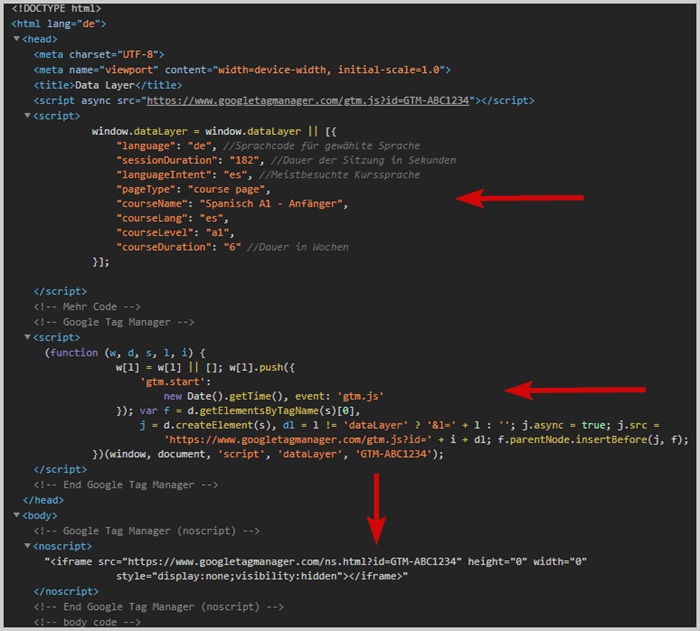
Der Data Layer code wird oben im Quelltext vor dem Tag Management System implementiert, damit die Daten zugänglich sind, wenn das TMS lädt.
Beispiel: Data Layer Positionierung im Quelltext
3. Debugging
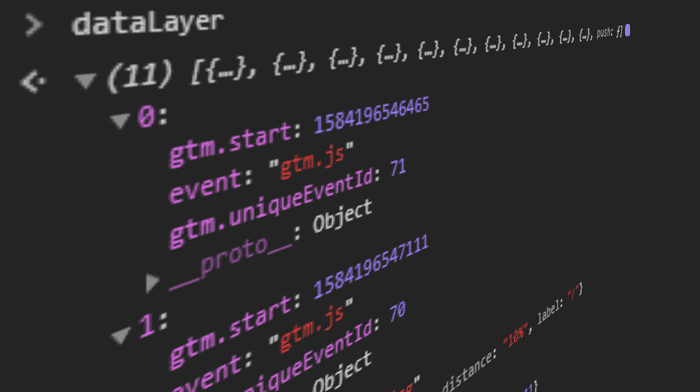
Die typischen Szenarien zum Debuggen eines Data Layers sind entweder, das Auslesen von Data Layer Variablen oder das Simulieren von Ereignissen, um zu sehen, wie sich der Data Layer verändert.
Da das Data Layer Objekt global zugänglich ist, können Variablenwerte einfach in der Browserkonsole ausgelesen werden.
Um den Data Layer zu untersuchen, kannst Du die folgenden Variablennamen in der Browserkonsole eingeben (vorausgesetzt die üblichen Namenskonventionen werden genutzt):
Webseiten mit GTM DataLayer
Object.assign(...dataLayer)
Webseiten mit Adobe Launch oder DTM Data Layer
digitalData
Tealium Data Layer
utag.data oder utag_data
Google Tag Manager hat sogar einen eigenen Debugger Mode, der aktiviert wird, wenn man oben rechts auf in Vorschau ansehen klickt.
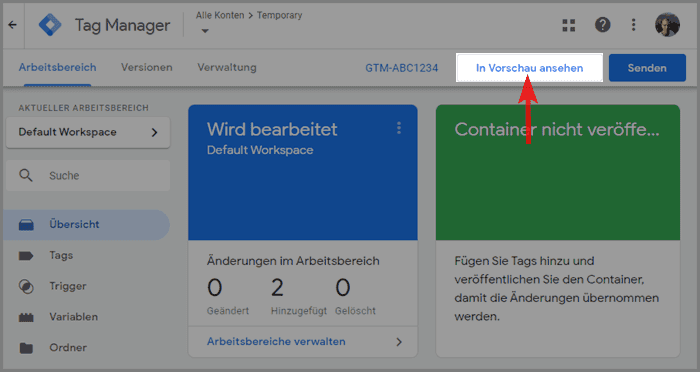
Falls man keinen Zugang zum Tag Management Container auf einer Webseite hat, aber trotzdem den Data Layer debuggen möchte, kann man auch eine Data Layer Chrome Extension nutzen.
Data Layer Chrome Extensions
Es gibt eine Vielzahl an potentiellen Data layer Extensions zum Debuggen von Analytics und Tag Management Systemen. Ich bevorzuge die Extensions, die die meisten Systeme und Anbieter unterstützen, damit ich nicht dauernd wechseln muss.
Die folgenden Chrome Extensions sind zur Zeit meine Favoriten beim Data Layer Debugging:
- Trackie - Extension basierend auf Data Slayer und open source, aber mit guter Performance und unterstützt GTM, DTM, Tealium’s Data Layer und viele mehr
- Omnibug - Allrounder mit Unterstützung für Adobe DTM, Launch und Analytics, sowie Matomo, GTM, Tealium und mehr
Extensions für Google Analytics und GTM
- GTM/GA Debug - Nach der Aktivierung ist ein neuer Tab in Chrome DevTools (F12, oder strg+shift+i) zugänglich. Alle relevanten Daten werden in einem grafischen UI angezeigt und können über mehrere Seitenaufrufe hinweg angezeigt werden.
- Adswerve - dataLayer Inspector+ - loggt alle relevanten Daten in die Browserkonsole. Man sollte in den Einstellungen der Browserkonsole “Preserve log” aktivieren, damit die Daten über mehrere Seitenaufrufe bestehen bleiben.
- Data Slayer - Definitiv die Data Layer Extension mit dem coolsten Namen und Logo und mein ehemaliger Favorit. Open source, schlichtes Layout und funktioniert auch mit Adobe DTM. Deaktiviere “use three-column layout where available”, “show GA Classic tags” und “show Floodlight tags” in den Einstellungen, ansonsten wirds zu unübersichtlich.
Chrome Erweiterungen zum Debuggen von Adobe Analytics, Launch, DTM und Tealium
- Launch & DTM Switch - Ermöglicht das Laden der Staging- oder Live-Bibliothek des Tag Management Systems und aktiviert den Debug-Mode.
- Debugger for Adobe Analytics - schaltet den Debugging Mode an. Alternativ kann auch
_satellite.setDebug(true)in der Browserkonsole eingegeben werden. - Adobe Experience Cloud Debugger - Meta extension zum Debuggen aller Adobe Lösungen.
- Adobe Experience Platform Debugger - Nachfolger vom Experience Cloud Debugger, der mehr Übersicht bietet (derzeitig noch in Beta).
- Tealium Data Layer Debugger - Simpel und übersichtlich.
E-Commerce Data Layer
Data Layer für E-Commerce Webseiten sind umfangreicher und in ihrer Struktur komplexer. Sie müssen eine erheblich größere Anzahl an Informationen und Ereignissen verwalten und sind daher aufwendiger in der Planung und Implementierung.
Bei Google Analytics funktioniert der E-Commerce Report erst, wenn ein entsprechender E-Commerce Data Layer implementiert ist.
Große Webshops erfordern jedoch fortgeschrittenere Tracking Setups, weshalb bei Google Analytics spezielle Data Layer für enhanced E-Commerce implementiert werden.
Bei E-Commerce Data Layern für Google Analytics müssen die Vorgaben für Datenstruktur und Variablennamen befolgt werden, damit die E-Commerce Reports in GA funktionieren.
Bei anderen Analytics Platformen muss man keinen Vorgaben folgen und kann den Data Layer selbst designen.
Wann ist ein Data Layer nicht notwendig?
Ein Data Layer braucht nicht unbedingt implementiert werden, wenn der Mehraufwand die vermeintlichen Vorteile nicht rechtfertigt.
Im obigen Beispiel haben wir verschiedene Daten aus mehreren Quellen (Frontend, Backend, API) und lösen die damit verbundenen Tracking Probleme mit einem Data Layer.
Viele Webseiten (sog. "Brochure-Webseiten") haben jedoch gar keine Login-Funktion und somit keine Datenbank mit Nutzerdaten.
Die Häufigkeit von Änderungen auf der Webseite spielt außerdem eine entscheidende Rolle, da Änderungen die Selektoren für gewisse Elemente brechen könnten.
Vor allem private Blogs oder Webseiten von kleinen Betrieben durchlaufen jedoch selten wesentliche Veränderungen im Quellcode der Seite. Selbst Enterprises haben manchmal nur Brochure-Websites mit 50 Unterseiten auf denen ein Kontaktformular die härteste Konvertierung darstellt.
Insofern die benötigten Daten auf erforderlichen Unterseiten verfügbar sind und von wenigen Änderungen auszugehen ist, kann daher ein Web Analytics Setup ohne Data Layer aufgezogen werden. Ein Data Layer würde das Datensammeln nicht wesentlich sicherer, robuster oder einfacher machen. Der Gewinn entschuldigt daher nicht den Mehraufwand.
Typische Beispiele wann ein Data Layer unnötig ist, sind also Broschür- oder Content-Webseiten mit wenigen bzw. gar keinen harten Konvertierungn. Üblicherweise beschränkt sich die Analyse auf das Herunterbrechen von Ereignissen über Inhaltskategorien.
Solche Anforderungen an ein Analytics Setup können daher schon mit fortgeschrittenem JavaScript und einem durchdachten System zur Inhaltsstrukturierung erfüllt werden.
Sobald das direkte Einsammeln von Daten via CSS-Selektoren zu aufwändig wird und auf jeden Fall, wenn Daten aus der Datenbank benötigt werden, ist ein Data Layer jedoch die Empfehlung.
Alternative Lösungen sind ggf. kurzfristig zufriedenstellend, brechen jedoch in der Regel irgendwann und sind schwierig in Stand zu halten.
Ein Data Layer hat auf lange Sicht gute Chancen zu bestehen, da er ein zentrales Konzept in der Web Analytics Branche darstellt und Webbüros zunehmend Erfahrung mit der Implementierung haben. Bei einem Bürowechsel kann also davon ausgegangen werden, dass der Data Layer übernommen und in Stand gehalten wird.
Fazit
Ein Data Layer ist der Standard für professionelle Analytics Setups. Er erhöht die Datenqualität und verbessert damit die Datenanalyse generell, ohne die Sicherheit von Kundendaten zu gefährden.
Für ambitionierte Webseitenbetreiber die umfangreiche Datenanalyse betreiben wollen, ist ein Data Layer die einfachste, robusteste Lösung.
Wer die Wahl hat, sollte eine Array-basierten Data Layer Struktur implementieren. Sie ist flexibler, hat weniger Abhängigkeiten und eignet sich für alle Typen von Webseiten.
Content-Webseiten sind hingegen in ihrer Funktionalität vergleichsweise simpel und brauchen nicht unbedingt einen Data Layer, insofern von wenigen Änderungen ausgegangen werden kann. Dies gilt vor allem wenn die benötigten Daten auf den Seiten verfügbar sind bzw. über Umwege verfügbar gemacht werden können.
Wer selber einen Data Layer implementieren will, hat es mit Wordpress am einfachsten. Umfangreiche Projekte sollten jedoch zusammen mit einem Analytics Consultant geplant und gesteuert werden, um Zeit und Implementierungskosten zu sparen.
Ich empfehle Interessierten sich auf jeden Fall eine Data Layer Chrome Extension zu installieren und damit einige populäre Webseiten zu inspizieren - aus generellem Interesse und um Inspiration zu neuen Erfolgsindikatoren (KPIs) zu finden 😉.
Data Layer Dokumentation der verschiedenen TMS-Anbieter
- Google Tag Manager: Erstellung und Änderungen des Data Layers
- Adobe Launch: Erstellung des Data Layers
- Tealium iQ: Erstellung und Änderungen des Data Layers
- Matomo: Erstellung und Änderungen des Data Layers
- Piwik Pro: Erstellung und Änderungen des Data Layers
FAQ
Was ist ein Beispiel für einen Data Layer?
Ein Beispiel für einen Data Layer wird im Artikel gegeben. Ein JavaScript-Objekt speichert Daten von einer Website, Datenbank oder einer externen Quelle auf zentrale, flexible und leicht zugängliche Weise. Ein Beispielcode-Snippet für die Initiierung eines Data Layers für Google Tag Manager ist: window.dataLayer = window.dataLayer || [{ "pageCategory": "Kategorieseite", "pageName": "Sneaker-Übersicht", "language": "en-US",}];
Was sind Data Layer Variablen?
Data Layer Variablen sind Schlüssel-Wert-Paare innerhalb des Data Layers, die spezifische Informationen speichern. Diese Variablen können Seitenmerkmale, Benutzerverhaltensdaten und mehr umfassen und dienen als zentrales Datenrepository für Analytik und Tracking.
Warum sollte man einen Data Layer verwenden?
Ein Data Layer ist wesentlich für robuste, flexible und sichere Datensammlung. Er zentralisiert Daten aus verschiedenen Quellen, macht sie leicht zugänglich und konsistent über verschiedene Webseiten und Benutzerinteraktionen hinweg. Dieser Ansatz verbessert die Datenqualität und -zuverlässigkeit, was für datengesteuerte Entscheidungsfindung entscheidend ist.
Brauche ich einen Data Layer?
Obwohl nicht immer notwendig, wird ein Data Layer generell für diejenigen empfohlen, die ernsthaft ihre Datenanalyse-Ambitionen verfolgen. Er bietet Datenqualität, Zuverlässigkeit und langfristige Zeitersparnis, die den höheren Implementierungsaufwand rechtfertigen.
Was sind die Vorteile eines Data Layers?
Die Vorteile eines Data Layers umfassen: Verfügbarkeit von Daten unabhängig von ihrer Sichtbarkeit auf der Seite. Robuste Datensammlung. Verminderung von Datenverlust bei asynchronen Datenanfragen. Sichere Datensammlung aus mehreren Quellen.
Haben alle Websites einen Data Layer?
Nicht alle Websites haben einen Data Layer. Seine Implementierung hängt von der Komplexität der Website und der Tiefe der erforderlichen Datenanalyse ab. Einfache Websites haben möglicherweise keinen Data Layer, während komplexere Seiten, insbesondere solche, die auf datengesteuerte Entscheidungsfindung fokussiert sind, wahrscheinlich einen haben werden.
Wie greife ich auf den Data Layer zu?
Der Data Layer ist global in der Browser-Console zugänglich. Für Websites mit Google Tag Manager kannst du auf ihn dataLayer oder Object.assign(...dataLayer) zugreifen. Für Adobe Launch oder DTM kannst du ihn mit digitalData zugreifen.
Wie fügt man Daten zum Data Layer hinzu?
Um Daten zum Data Layer hinzuzufügen, verwendest du die Methode dataLayer.push(). Zum Beispiel: window.dataLayer.push({ "event": "Kursbuchung", "startWeek": "24" }); Diese Methode wird verwendet, um neue Daten oder Änderungen zum Data Layer hinzuzufügen. Der Event-Schlüssel kann verwendet werden, um eine weitere Tag-Ausführung im Tag-Management-System auszulösen.
Weitere Ressourcen
- Simo Ahava über den Data Layer in GTM mit praktischen Beispielen
- Lies mein Tutorial über das Google Tag Manager Einrichten
- Kevin Haag’s Präsentation vom Measurecamp Berlin 2019 über den Event Driven Data Layer in Adobe Analytics