Data Layer
I forbindelse med tag management og webanalyse, har du måske hørt udtrykket data layer. Det er det grundlæggende element i en ambitiøs webanalyseopsætning, fordi alle datapunkter og sporingsregler afhænger af det.
Derfor behandles det i digital analyse som et ufravigeligt krav for enhver analyseopsætning. Dog findes der også scenarier, hvor det ikke er nødvendigt.
Derfor vil jeg forklare hvad et data layer er, dets fordele, og forskellene mellem data layer for Google Tag Manager og Adobe Launch.
Derefter vil vi se på implementeringen for de mest populære Tag Management Systems (TMS). Jeg vil forklare design fasen, efterfulgt af implementering og debugging.
Hvad er et data layer?
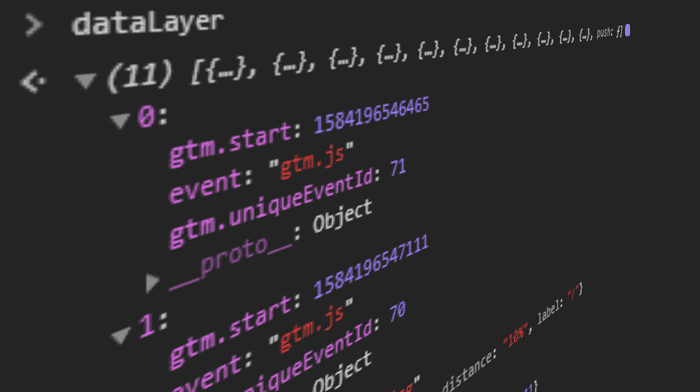
Et Data Layer er en datastruktur, der giver relevant information i Key-Value Pairs til brug med for eksempel Tag Management Systems.
Et Data Layer er tilgængeligt i den globale JavaScript-scope på hjemmesiden som en Array eller Object og holder data i en struktureret form til brug for andre programmer.
Fordelen ved et Data Layer ligger i en programmæssigt simpel adgang til relevant data under et besøg på en hjemmeside.
Det muliggør adgang til data på et centralt punkt og er grundlaget for dataanalyse-logikken i et tag management system.
window.dataLayer = window.dataLayer || [{"pageCategory": "category page","pageName": "sneaker overview","language": "en-US",}];
Da det bruges til at gemme data fra flere datakilder, forenkler det overvågningen af aktuelle dataværdier, fordi kun ét sted skal observeres ("single point of truth").
Et data layer bliver genopbygget ved hver sideload udstyret med datapunkter på den aktuelle webside og muligvis andre relaterede data om besøgende og deres besøg.
Bemærk: Single page applications (SPA) genindlæser ikke siden mellem navigering. Derfor er datalayer-konfigurationen for en single page application anderledes end for typiske websider med sideloads.
De holdte data repræsenterer egenskaber eller funktioner af en underside og holdes i en key-value-pair. Nøglerne holder beskrivende navne på funktionerne parret med en aktuel værdi, som typisk ændres under brugerens rejse.
window.dataLayer = window.dataLayer || [{"pageCategory": "category page", //category"pageName": "sneaker overview", //name"language": "en-US", //language}];
Det overordnede mål er at gøre disse datapunkter tilgængelige i tag management systemet, så de kan sendes sammen med dataen delt med f.eks. Google Analytics eller Facebook Ads for bedre at beskrive hjemmesideinteraktioner.
For at muliggøre denne integration holder TMS referencer til key-value-pairs og kan for eksempel udføre regler, når deres værdi ændres.
Eksempel: En besøgende zoomer ind på et produktbillede og udløser dermed en begivenhed "produktzoom". Uden yderligere data sendt sammen med begivenheden er det ikke meget indsigtsfuldt. Derfor sender vi også data om f.eks. produktnavn, kategori og pris, så vi kan analysere begivenheden i en meningsfuld kontekst.
De yderligere data gør det muligt at verificere, om sådanne produktzooms kun sker i bestemte produktkategorier. Hvis ja, kan det være gavnligt at tilføje flere billeder til andre produkter i samme kategori, da besøgende synes at være meget interesseret i billeddetaljerne af disse produkter.
Kort sagt strukturerer vi alle relevante data i beskrivende nøgler og værdier og gør dem tilgængelige på et centralt sted, hvor de nemt kan hentes.
Sådanne datapunkter er normalt vigtige egenskaber ved sideindholdet eller en klassifikation, vi har oprettet for at segmentere besøgende baseret på adfærd.
For bedre at forstå, hvad et data layer er, som en forenklet visualisering, kan du forestille dig et Excel-ark. Arkene holder vigtige egenskaber om en webside i sin header (sti, sprog, kategori, logget-ind-status) sammen med en aktuel værdi for hver post.

Hvad er fordelene ved at bruge et data layer?
Mens en besøgende navigerer gennem en hjemmeside, sker der mange brugerinteraktioner: klik på knapper, udfyldning af formularer eller afspilning af videoer.
Hvis disse interaktioner giver os mulighed for at drage konklusioner om brugerengagement, sendes de f.eks. til Google Analytics sammen med andre beskrivende data om den besøgende, sessionen, begivenheden selv eller det HTML-element, de interagerede med.
Og dette er det afgørende punkt: De ekstra data til at beskrive sådanne interaktioner kommer fra forskellige datakilder, for eksempel fra frontend, database eller en ekstern API.
For at forstå fordelene ved et data layer, skal vi først forstå udfordringerne, der opstår, når vi har brug for data fra flere datakilder.
Lad os se på et eksempel, hvor vi indsamler data fra sådanne kilder, og lad os tænke det igennem:
Eksempel: Den besøgende køber et produkt på en hjemmeside. Følgende dimensioner kunne være interessante:
- produktnavn
- produktpris
- produktstørrelse
- produktkategori
- produktfarve
- indkøbskurvværdi
- mærke
- første køb
- kundesegment
- kundens rabat
- køn
- land
Efter købet lander de besøgende på en takkeside, der viser alle detaljer om købet og leveringsadressen.
Frontend: For at sende produktdata, indkøbskurvværdi og mærke sammen med begivenheden, kan vi potentielt skrabe det fra takkesiden.
Den største udfordring ved at skrabe data fra en webside er, at dataene skal være tilgængelige på hver side, hvor interaktionen finder sted. Dette er sjældent tilfældet i virkeligheden.
Det er tilrådeligt at måle så mange af de samme dimensioner på tværs af alle interaktioner på en hjemmeside for at gøre interaktionerne sammenlignelige senere under dataanalyse. Derfor, hvis vi skulle følge denne tilgang, er det sandsynligt at andre sider ikke viser produktdata, indkøbskurvværdi og mærke for at sende sammen med andre begivenheder.
Så hvis de nødvendige data ikke er tilgængelige på andre sider, vil vi undgå at tilføje alle de data til indholdet bare for analysens skyld. Det er derfor, vi bruger et data layer. Det gør dataene tilgængelige for os at indsamle, uanset om de er synlige på siden eller ej. Det er bogstaveligt talt et lag af data, der ligger oven på en given underside, og leverer de data, vi har brug for.
En anden udfordring ved at skrabe data fra frontend er, at det til sidst går i stykker. Når sider ændres og disse ændringer påvirker HTML-strukturen af de skrabede elementer, vil dataindsamlingen gå i stykker. Især i større virksomheder er der hyppige ændringer på sider og flere teams, der arbejder på dem uden at vide, om nogle HTML-elementer er nødvendige for dataindsamling. Derfor vil enhver skrabning af data fra frontend på et tidspunkt gå i stykker på hyppigt opdaterede hjemmesider.
Et data layer udnytter denne tilgang og gør det muligt at hente brugerdata på en sikker og enkel måde.
Database: Indsamling af kundedata (kundesegment, rabat, køn og første køb) kan blive lidt tricky: Kundedata skal enten sendes sammen med serverens svar eller med en separat API.
Men da dette er private data, skal indsamlingen være godkendt af hensyn til databeskyttelse. Det betyder, at en API-anmodning ikke kunne håndteres i browseren, fordi API-nøglen ellers ville kunne hentes af erfarne brugere.
Derfor er den bedste løsning at sende dataene sammen med serverens svar baseret på hjemmesidens login-autentificering.
Når brugeren er logget ind, bliver data layer udfyldt med de relevante data fra databasen. Uden login, bliver ingen følsomme data eksponeret.
API: Geo data såsom landet kunne hentes fra en ekstern service API.
Dog opstår den samme udfordring som ved hentning af data fra databasen: Enhver API-anmodning fra frontend eller tag management systemet kræver en API-nøgle, som ikke bør håndteres i browseren af sikkerhedsmæssige årsager.
En anden ulempe ved at arbejde med API'er til dataindsamling, især med hændelser, er varigheden indtil dataene kommer tilbage. Hvis en bruger navigerer til en anden side, før dataene er ankommet, risikerer vi at miste hændelsen.
Lad os hurtigt opsummere fordelene:
Fordele
- Data er tilgængelig, uanset om den er synlig på siden
- Robust dataindsamling
- Sikker indsamling af følsomme data
- Reducerer datatab ved asynkrone dataanmodninger
Hvorfor du sandsynligvis har brug for et
Ved at oprette et data layer bliver et JavaScript-objekt tilgængeligt i den globale scope i browseren ved hver sideload.
Dataene, det indeholder, kan stamme fra din database, frontend eller API'er, så dataindsamling fra disse kilder bliver pålidelig, sikker og uafhængig af HTML på siden.
Data fra databasen kan gøres tilgængelig på enhver underside af hjemmesiden uden meget besvær uden at være synlig i indholdet.
Af ovenstående grunde råder jeg generelt klienter til at implementere data layers, hvis de er seriøse omkring deres dataanalyseambitioner. Fordelene ved datakvalitet, pålidelighed og de tilknyttede langsigtede tidsbesparelser retfærdiggør de højere implementeringsomkostninger.
Det ultimative mål med webanalyse er at træffe databaserede forretningsbeslutninger, så datakvalitet bør være en prioritet.
Lad os nu se på de forskellige tilgængelige muligheder og nogle implementeringseksempler, før vi dykker ned i design- og implementeringsfasen.
Data Layer for Adobe Analytics, DTM, Launch og Tealium
Data Layers kan have forskellige strukturer. Generelt skelner vi mellem dem, der kommer med en objekt-baseret struktur og en array-baseret struktur.
Ifølge data layer definition fra World Wide Web Consortium (W3C) følger syntaksen den for et JavaScript-objekt. Det er uofficielt forkortet CEDDL (Customer Experience Digital Data Layer).
Du kan også indlejre andre objekter eller arrays i det:
window.digitalData = {pageName: "sneaker oversigt",destinationPath: "/da/sneakers",breadCrumbs: ["hjem","sneakers"],publishDate: "2020-07-01",language: "en-US"};
Adobe Analytics, Adobe Launch og Tealium følger CEDDL-strukturen. I eksemplet ovenfor gemmer vi data i et objekt kaldet digitalData. Navnet er ikke standardiseret og kan vælges frit, men du skal erklære navnet i tag management systemet.
For at ændre dataene er der flere muligheder (som med ethvert JS-objekt), men den enkleste måde er bare at overskrive værdierne:
window.digitalData.language = "da-DK";
Hovedideen med den objekt-baserede struktur er, at de kun indlæses pr. sideload, men de ændres ikke meget baseret på brugerinteraktion. Dataene er for det meste statiske.
Hændelsessporing er ikke drevet af hændelser, der indgår i data layer-objektet. Hændelser spores med en separat sporingsbibliotek til at sende dem videre til en analyseplatform f.eks. Adobe Analytics. Når hændelsessporingskoden udføres, sendes data layer-objektet med i sin helhed og kan bruges under dataanalyse.
//Event med valgt farve_satellite.setVar("sneaker farve", "sort");_satellite.track("vælg farve");
Brug Adobe Launch med et array-baseret data layer
Du kan nemt bruge Adobe Launch med en array-baseret struktur. Adobe Launch Extension Data Layer Manager gør det muligt.
Her er nogle links til yderligere ressourcer til brug af den array-baserede version med Adobe Launch:
- Jim Gordon’s Demo af brug af Data Layer Manager med Adobe Launch
- Data Layer Manager Extension med dokumentation
Data Layer for Google Tag Manager, Matomo og Piwik Pro
Data layer for Google Tag Manager, Matomo og Piwik Pro er array-baseret og uofficielt omtalt som event-driven data layer (EDDL).
Data håndteres også i objekter, men den overordnede struktur af GTM data layer er en array med objekter.
window.dataLayer = window.dataLayer || [{"pageCategory": "category page","pageName": "sneaker overview","language": "en-US",}];
Tracking-logikken med en array-baseret struktur er anderledes: Nye data eller ændringer skubbes ind i den via dataLayer.push(). Så en push til data layer kan udløse tag-eksekveringer i tag management systemet.
Den grundlæggende forskel fra en objekt-baseret struktur er, at ændringer normalt sendes sammen med en hændelse og at regler udløses baseret på disse ændringer uden noget ekstra bibliotek, bare ved at observere om data layer-array ændres.
Da intet andet bibliotek som _satellite er nødvendigt, kræver vi en afhængighed mindre.
En anden egenskab ved den array-baserede tilgang er, at data ændres ret ofte i løbet af brugerrejsen, da enhver brugerinteraktion kan ændre data layer-variablerne.
Så en array-baseret data layer er grundlaget for event tracking og håndterer data mere fleksibelt, mens en objekt-baseret snarere tjener som et statisk datalager.
Gennem denne fleksibilitet siges en array-baseret data layer-struktur at være mere velegnet til Single-Page-Applications.
Du kan dog også spore SPAs med en objekt-baseret data layer, det vil bare kræve nogle flere linjer kode og potentielt nogle få kanttilfælde at løse.
Hvis du er i begyndelsen af et projekt og har valget, vil jeg foretrække en array-baseret data layer.
At ændre en allerede eksisterende opsætning fra en objektstruktur til en array er dog unødvendigt.
Content Management Systems med data layer inkluderet
WordPress-brugere har det nemt, da de kan bruge dette plugin til at implementere Google Tag Manager sammen med et forudkonfigureret data layer.
Det fyldes automatisk med kategorier, forfatternavne, udgivelsesdatoer og søgeord.
Datapunkterne kan tjekkes eller fjernes i plugin-indstillingerne. Desuden tilbyder plugin'et forudkonfigurerede hændelser for formularindsendelser fra de mest almindelige formularplugins.
Hvis du er webshop-ejer og bruger WooCommerce til WordPress, kan du implementere et klassisk e-handels data layer samt et forbedret e-handels data layer med det samme plugin, hvilket er ret kraftfuldt.
WordPress-brugere, der vil bruge Tealium, kan bruge et plugin til Tealium.
Drupal har også et plugin.
Wix og Squarespace-brugere kan implementere Google Tag Manager gennem platformens værktøjer, men skal implementere data layer-koden manuelt.
Data layer implementering
Så hvordan implementerer du et data layer? - Da planlægning og implementering kræver viden på tværs af områderne digital analyse, frontend udvikling og backend udvikling, udføres implementeringen normalt af et webbureau sammen med en analytics konsulent.
Analytics konsulenten briefer webbureauet og leder projektet, indtil implementeringen er succesfuldt valideret. Derefter konfigureres tag management systemet og analyseværktøjerne.
Hvis du er interesseret og kender lidt til JavaScript, kan du implementere det selv med følgendeimplementeringsguide.
Implementeringen går gennem 3 trin:
1. Data Layer Design
Designfasen handler om at definere, hvilke interaktioner der skal måles sammen med hvilke dimensioner.
Enhver attribut af den besøgende, sessionen, siden, produktet eller hændelsen kan være af potentiel interesse under dataanalyse og bør overvejes til data layer-arkitekturen.
For at beslutte hvad der skal inkluderes, start med slutmålet i tankerne og spørg dig selv, hvilke forretningskritiske spørgsmål der skal besvares, og indsnævr de relaterede datapunkter.
Næste skridt er at finde ud af, hvordan disse datapunkter skal struktureres, og hvilke dimensioner der er de vigtigste at tilføje.
Eksempel: En sprogskole, der driver en WordPress-hjemmeside på flere sprog, vil gerne vide de besøgendes modersmål og hvilket fremmedsprog, de er mest interesserede i. Målet er potentielt at køre online annoncering via Facebook Ads målrettet demografiske grupper med lignende attributter.
Som næste skridt skal vi definere alle relevante data på tværs af forskellige typer sider (hjemmeside, kurssider, om os, kontakt og nyheder). For at forenkle, lad os se på de mest interessante sider og fokusere på forsiden og kurssider.

Eksempel: Array-baseret Google Tag Manager data layer for en sprogskole
window.dataLayer = window.dataLayer || [{"language": "da", //Sprog for UI"sessionDuration": "182", //Sessionsvarighed i sek"languageIntent": "es", //mest besøgte kurssprog"pageType": "kursside","courseName": "Spansk A1 - Begynder","courseLang": "es","courseLevel": "a1","courseDuration": "6" //Varighed i uger}];
Eksempel: Objekt-baseret data layer for Adobe Launch
window.digitalData = window.digitalData || {"language": "da", //Sprog for UI"sessionDuration": 182, //Sessionsvarighed i sek"languageIntent": "es", //mest besøgte kurssprog"pageType": "kursside","courseName": "Spansk A1 - Begynder","courseLang": "es","courseLevel": "a1","courseDuration": 6 //Varighed i uger};
2. Implementering
Data layers skal implementeres på hver underside af en hjemmeside. De ovenstående kodeeksempler viser dog den endelige beregnede tilstand.
Under implementeringen skal datapunkterne først hentes for at blive beregnet til deres endelige tilstand, så den faktiske kilde kommer til at se lidt anderledes ud.
For at give et realistisk eksempel antager jeg følgende:
- Sessionsvarighed og sproginteresse indsamles gennem et speciallavet JavaScript og holdes i browserens lokale lagring.
- Sprog, sidetype og kursusdata kan hentes fra databasen via serverens svar og gøres tilgængelige på kursskabeloner og forsiden.
Kildekoden for data layer i backend ifølge ovenstående forudsætninger vil se sådan ud:
window.dataLayer = window.dataLayer || [{"language": <?php echo wpb_getpagedata("lang"); ?>,"sessionDuration": window.localStorage.sessionDuration,"languageIntent": window.localStorage.languageIntent,"pageType": <?php echo wpb_getpagedata("type"); ?>,"courseName": <?php echo wpb_getcoursedata("name"); ?>,"courseLang": <?php echo wpb_getcoursedata("lang"); ?>,"courseLevel": <?php echo wpb_getcoursedata("level"); ?>,"courseDuration": <?php echo wpb_getcoursedata("duration"); ?>,}];
Event tracking med data layer push
For at sende events til et GTM data layer kan du bruge dets push-metode og bogstaveligt talt skubbe events ind i det.
window.dataLayer.push({"event": "course-booking","startWeek": "24"});
Event-nøglen er en speciel nøgle og kan adresseres som en custom event fra GTM containeren.
Tag management systemet observerer data layer og eksekverer et tag, så snart en foruddefineret custom event er sendt til det.
Efter en event er tilføjet, kan TMS for eksempel sende en event til Google Analytics.
Al relevant data for at give kontekst (navn, sprog, sprogniveau, kursusvarighed) er tilgængelig og kan sendes sammen med eventen, for eksempel startugen for kurset.
I et objekt-baseret data layer vil den samme event blive sendt direkte til Adobe Analytics via deres eget event tracking-bibliotek.
For Adobe Launch vil eksempel koden se sådan ud:
_satellite.setVar("startWeek", 24);_satellite.track("course-booking");
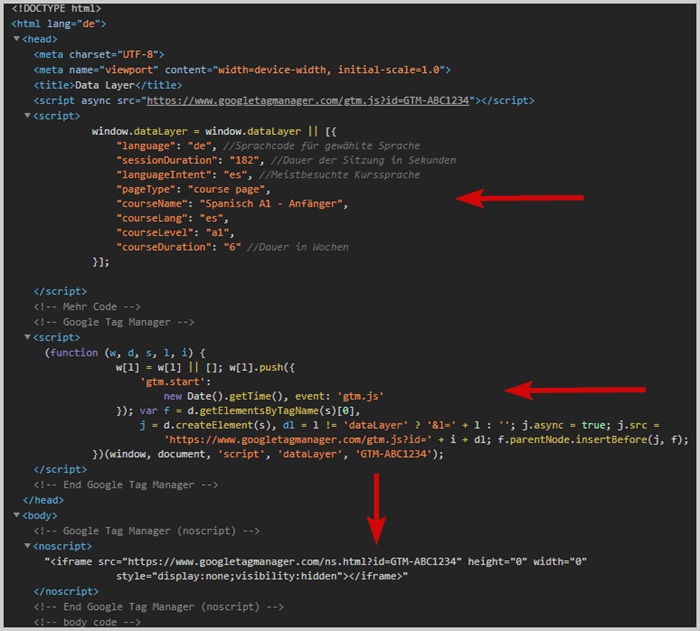
Kodens placering i kildekoden
Data layer-koden skal tilføjes i <head> på siden før tag management systemet.
På grund af denne rækkefølge sikrer du, at den allerede er beregnet, når tag management systemet vil få adgang til den.
Eksempel: Placering i kildekoden
3. Fejlfinding
De mest almindelige procedurer til at fejlfinde et data layer er at simulere sideloads eller hændelser for at verificere, at alle datapunkter udfyldes med de korrekte data.
Da det er globalt tilgængeligt i browserens konsol, kan du blot udskrive alle værdier til konsollen (forudsat at standardnavnekonventioner anvendes):
Websites med GTM
Object.assign(...dataLayer)
Websites med Adobe Launch eller DTM
digitalData
Tealium
utag.data eller utag_data
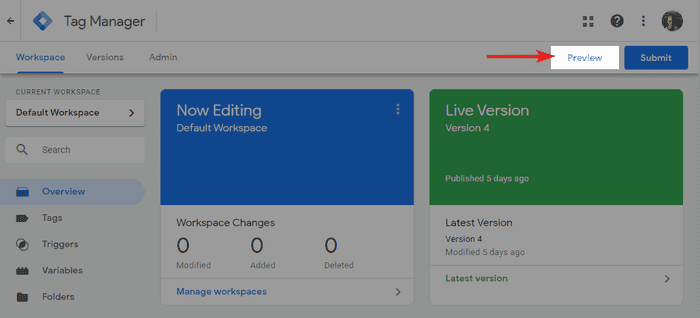
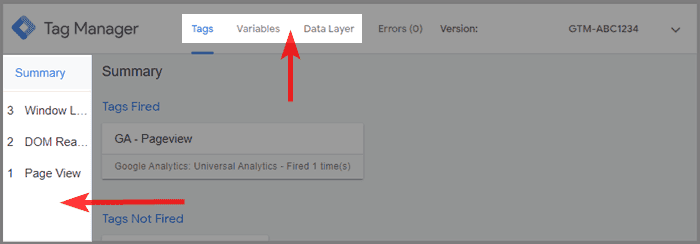
Google Tag Manager har endda sin egen Debugger Mode. Du kan aktivere den fra GTM interfacet ved at klikke på preview i øverste højre hjørne.
Hvis du ikke har adgang til tag management containeren, men alligevel vil fejlfinde den, kan du bruge en chrome-udvidelse.
Data Layer Chrome-udvidelser
Der er en række potentielle udvidelser til fejlfinding derude. Jeg foretrækker dem, der understøtter de fleste udbydere, så jeg ikke behøver at skifte mellem udvidelser, når jeg fejlfinder en anden hjemmeside.
Følgende chrome-udvidelser er i øjeblikket mine favoritter til fejlfinding:
- Trackie - Udvidelse baseret på Data Slayer og open source. Den har en ret god ydeevne og understøtter GTM, DTM, Tealium og mange flere.
- Omnibug - En anden all-rounder med support til Adobe Analytics (DTM & Launch) samt Matomo, GTM, Tealium og flere.
Chrome-udvidelser til fejlfinding af Google Analytics og GTM
- GTM/GA Debug - efter aktivering af udvidelsen vil der være en ny fane tilgængelig i Chrome DevTools, når du åbner dem (F12 på Windows og CTRL+SHIFT+i på Mac). Alle relevante data vises i en grafisk brugergrænseflade, og den opdateres, mens du browser en hjemmeside.
- Adswerve - dataLayer Inspector+ - logger alle relevante datapunkter ind i browserens konsol. Aktivér "preserve log" i konsolindstillingerne for at beholde logs på tværs af sidenavigation.
- Data Slayer - absolut udvidelsen med det fedeste navn og logo og min tidligere favorit. Det er open source med et simpelt layout og fungerer også med Adobe DTM.
Fjern markeringen af “use three-column layout where available”, “show GA Classic tags” og “show Floodlight tags” i udvidelsesindstillingerne, ellers bliver logs lidt rodede.
Chrome-udvidelser til fejlfinding af Adobe Analytics, Launch og DTM
- Launch & DTM Switch - giver dig mulighed for at indlæse staging- eller produktionsbiblioteket i tag management systemet og kan aktivere debug-tilstand.
- Debugger for Adobe Analytics - aktiverer debug-tilstand. Alternativt kan du også skrive
_satellite.setDebug(true)i konsollen. - Adobe Experience Cloud Debugger - metaudvidelse til at fejlfinde alle Adobe-produkter.
- Adobe Experience Platform Debugger - efterfølger til experience cloud debugger, der tilbyder et bedre overblik (i øjeblikket stadig i beta).
- Tealium Data Layer Debugger - simple tabeller over alle aktuelle værdier.
E-Commerce Data Layer
Data layers for e-handel er mere omfattende, og deres struktur er mere kompleks. De skal indeholde flere data og håndtere flere hændelser.
Derfor tager planlægningen og implementeringen af en e-handels hjemmeside betydeligt længere tid.
E-handelsrapporten i Google Analytics viser for eksempel ingen data, hvis implementeringen ikke følger deres e-handels data layer dokumentation.
Store e-handelsbutikker kræver dog endnu mere avancerede tracking-opsætninger. De implementerer en data layer for enhanced e-commerce, som muliggør endnu mere funktionalitet i Google Analytics.
Du skal følge implementeringsretningslinjerne for Google Analytics nøje for at få e-handelsrapporterne til at fungere. Det gælder både data layer-strukturen og variabelnavne.
Hvis du vælger en anden analyseplatform til e-handel, er du fri til at planlægge strukturen, som du vil.
Hvornår er et data layer ikke nødvendigt?
Som med alt andet er der også tilfælde, hvor den ekstra indsats ved implementering af et data layer ikke er berettiget.
I de ovenstående eksempler kiggede vi på tilfælde, hvor vi hentede data fra forskellige datakilder (Frontend, Backend, API) og løste problemer, der opstod ved at arbejde med en række datakilder.
Mange hjemmesider (såkaldte brochure-websites) har dog ikke engang en login-funktionalitet, og de har heller ikke en database.
En anden vigtig faktor er, hvor ofte ændringer implementeres på hjemmesiden. Mange sider gennemgår sjældent deres indhold eller tilføjer funktionalitet regelmæssigt. Jeg ser endda virksomheder køre simple brochure-websites med omkring 50 undersider og en kontaktformular som den hårdeste konvertering.
Da sådanne sider sandsynligvis kun kræver data fra frontend for at udføre deres dataanalyse, kunne de klare sig med en simpel analyseopsætning uden noget data layer. Det ville ikke gøre indsamlingen meget mere robust eller sikker, så dens fordele mindskes. Under sådanne omstændigheder retfærdiggør fordelene ikke den ekstra indsats ved implementeringen.
Typiske eksempler på, hvornår et data layer ikke er nødvendigt, er brochure-websites eller indholdshjemmesider med et begrænset antal eller næsten ingen hårde konverteringer. Normalt er sådanne sideejere simpelthen interesserede i at kategorisere brugerengagement efter deres indholdssektioner eller nogle interne virksomhedsklassifikationer.
Sådanne krav kan opnås med noget avanceret JavaScript og et gennemtænkt system til strukturering af indholdet.
Så snart dataindsamling fra frontend regelmæssigt går i stykker og bestemt når en database skal involveres, anbefales et data layer.
Alternative løsninger er ofte kun midlertidigt tilfredsstillende på grund af stigende analyseambitioner og regelmæssigt svigtende dataindsamling. Derudover er enhver specialløsning normalt svær at overdrage til et andet bureau.
Et data layer har gode chancer for at overleve tidens test, fordi det allerede er et etableret koncept inden for webanalyse, så webbureauer har stigende erfaring med at implementere og vedligeholde et.
Konklusion
Et data layer er guldstandarden for professionelle analyseopsætninger. Det øger datakvaliteten og forbedrer dermed dataanalysen som helhed, samtidig med at det opfylder sikkerhedskrav.
For ambitiøse hjemmesideejere, der ønsker at starte med seriøs dataanalyse, er det den nemmeste og mest robuste løsning.
Hvis du har valget, implementer en array-baseret struktur, da du har færre afhængigheder og kan bruge den på alle slags hjemmesider.
Indholdshjemmesider er dog så begrænsede i funktionalitet og har normalt kun et begrænset antal hårde konverteringer, så et data layer kan potentielt undværes. Dette gælder især, hvis alle nødvendige data er tilgængelige på siderne eller kan gøres tilgængelige gennem nogle omveje.
Hvis du vil implementere et selv, er det sandsynligvis nemmest at gøre det med en WordPress-hjemmeside. Enhver avanceret krav er dog sandsynligvis ikke værd at bruge tid på og risikere et utilfredsstillende resultat.
Derfor er implementering med hjælp fra en analytics konsulent normalt vejen at gå, da det sparer tid og undgår unødvendige risici.
Jeg anbefaler, at du installerer en af de nævnte chrome-udvidelser for at inspicere data layers på nogle større hjemmesider derude. Det er normalt en stor inspiration og giver nogle interessante KPI'er, der potentielt kan integreres i dine egne analyseopsætninger 😉.
Data Layer dokumentation fra forskellige TMS-udbydere
- Google Tag Manager: Initiering og ændring af data
- Adobe Launch: Initiering
- Tealium iQ: Initiering og ændring af data
- Matomo: Initiering og ændring af data
- Piwik Pro: Initiering og ændring af data
FAQ
Hvad er et data layer eksempel?
Et data layer eksempel er givet i artiklen. Et JavaScript-objekt gemmer data fra en hjemmeside, database eller en ekstern kilde på en central, fleksibel og let tilgængelig måde. Et eksempel på kode til at starte et data layer for Google Tag Manager er: window.dataLayer = window.dataLayer || [{ "pageCategory": "category page", "pageName": "sneaker overview", "language": "en-US",}];
Hvad er data layer variabler?
Data layer variabler er nøgle-værdi par inden for data layer, der gemmer specifikke informationer. Disse variabler kan inkludere sideegenskaber, brugeradfærdsdata og mere, og fungerer som et centralt data repository til analyse og sporing.
Hvorfor bruge et data layer?
Et data layer er essentielt for robust, fleksibel og sikker dataindsamling. Det centraliserer data fra forskellige kilder, hvilket gør det let tilgængeligt og konsistent på tværs af forskellige websider og brugerinteraktioner. Denne tilgang forbedrer datakvaliteten og pålideligheden, hvilket er afgørende for databaseret beslutningstagning.
Har jeg brug for et data layer?
Selvom det ikke altid er nødvendigt, anbefales et data layer generelt til dem, der er seriøse med deres dataanalyseambitioner. Det giver datakvalitet, pålidelighed og langsigtede tidsbesparelser, der retfærdiggør de højere implementeringsomkostninger.
Hvad er fordelene ved et data layer?
Fordelene ved et data layer inkluderer: Tilgængelighed af data uanset dets synlighed på siden. Robust dataindsamling. Reduktion af datatab ved asynkrone dataanmodninger. Sikker dataindsamling fra flere kilder.
Har alle hjemmesider et data layer?
Ikke alle hjemmesider har et data layer. Dets implementering afhænger af hjemmesidens kompleksitet og dybden af den krævede dataanalyse. Enkle hjemmesider har måske ikke et data layer, mens mere komplekse sider, især dem der fokuserer på databaseret beslutningstagning, sandsynligvis vil have det.
Hvordan får jeg adgang til data layer?
Data layer er globalt tilgængeligt i browserens konsol. For hjemmesider med Google Tag Manager kan du få adgang til det ved at bruge dataLayer eller Object.assign(...dataLayer). For Adobe Launch eller DTM kan du få adgang til det ved at bruge digitalData.
Hvordan skubber man til data layer?
For at skubbe til data layer bruger du dataLayer.push()-metoden. For eksempel: window.dataLayer.push({ "event": "course-booking", "startWeek": "24" }); Denne metode bruges til at tilføje nye data eller ændringer til data layer. Event-nøglen kan bruges til at udløse en anden tag-eksekvering i tag management systemet.
Yderligere ressourcer
- Simo Ahava om data layer i GTM og hvordan man håndterer data i det.
- Læs min Google Tag Manager tutorial og lær at sætte det op.
- Kevin Haags præsentation fra Measurecamp Berlin 2019 om Event Driven Data Layer i Adobe Analytics