Data Lag
I forbindelse med tag management og webanalyse har du kanskje hørt begrepet data lag. Det er det grunnleggende elementet i et ambisiøst webanalyseoppsett fordi alle datapunkter og sporingsregler avhenger av det.
Derfor blir det i den digitale analyseverden behandlet som et ufravikelig krav for enhver analyseoppsett. Imidlertid finnes det også scenarier der det ikke er nødvendig.
Derfor vil jeg forklare hva et data lag er, dets fordeler, og forskjellene mellom data lag for Google Tag Manager og Adobe Launch.
Deretter vil vi se på implementeringen for de mest populære Tag Management Systems (TMS). Jeg vil forklare design-fasen, etterfulgt av implementeringen og feilsøking.
Hva er et data lag?
Et data lag er en datastruktur som gir relevant informasjon i nøkkel-verdi-par for bruk med for eksempel, Tag Management Systems.
Et data lag er tilgjengelig i det globale JavaScript-området på nettstedet som en Array eller Objekt og holder data i en strukturert form for andre programmer å bruke.
Fordelen med et data lag ligger i en programmessig enkel tilgang til relevant data under et nettstedbesøk.
Det muliggjør tilgang til data på ett sentralt punkt og er grunnlaget for dataanalyse logikken i et tag management system.
window.dataLayer = window.dataLayer || [{"pageCategory": "kategori side","pageName": "sneaker oversikt","language": "en-US",}];
Siden det brukes til å lagre data fra flere datakilder, forenkler det overvåkingen av gjeldende dataverdier, fordi bare ett enkelt sted må observeres ("single point of truth").
Et data lag blir gjenoppbygd ved hver sideinnlasting med data fra den aktuelle websiden og muligens andre relaterte data om besøkende og deres besøk.
Merk: Enkeltsideapplikasjoner (SPA) laster ikke siden på nytt mellom side navigeringen. Derfor er data lag-konfigurasjonen for en enkeltsideapplikasjon forskjellig fra typiske websider med sideinnlastinger.
De holdte dataene representerer egenskaper eller funksjoner på en underside og holdes i et nøkkel-verdi-par. Nøklene holder beskrivende navn på funksjonene sammenkoblet med en gjeldende verdi, som vanligvis endres under brukerens reise.
window.dataLayer = window.dataLayer || [{"pageCategory": "kategori side", //kategori"pageName": "sneaker oversikt", //navn"language": "en-US", //språk}];
Det overordnede målet er å gjøre disse datapunktene tilgjengelige i tag management systemet, slik at de kan sendes sammen med dataene som deles med f.eks. Google Analytics eller Facebook Ads for bedre å beskrive interaksjoner på nettstedet.
For å muliggjøre denne integrasjonen, holder TMS referanser til nøkkel-verdi-parene og kan for eksempel utføre regler når deres verdi endres.
Eksempel: En besøkende zoomer inn på et produktbilde og utløser dermed en hendelse "produktzoom". Uten ytterligere data sendt sammen med hendelsen, er det ikke veldig innsiktsfullt. Derfor sender vi også data om f.eks. produktnavn, kategori og pris, slik at vi kan analysere hendelsen i en meningsfull kontekst.
De ekstra dataene ville gjøre det mulig å verifisere om slike produktzooms bare skjer i visse produktkategorier. Hvis ja, kan det være gunstig å legge til flere bilder til andre produkter i samme kategori, siden besøkende ser ut til å være veldig interessert i bildedetaljene til disse produktene.
Poenget er at vi strukturerer alle relevante data i beskrivende nøkler og verdier og gjør dem tilgjengelige på et sentralt sted der de enkelt kan hentes.
Slike datapunkter er vanligvis viktige egenskaper ved sideinnholdet eller en klassifisering vi har kommet opp med for å segmentere besøkende basert på atferd.
For å bedre forstå hva et data lag er, som en forenklet visualisering, kan du tenke deg et Excel-ark. Arket holder viktige egenskaper om en webside i sin overskrift (sti, språk, kategori, innlogget status) sammen med en gjeldende verdi for hvert element.

Hva er fordelene med å bruke et data lag?
Mens en besøkende navigerer gjennom et nettsted, finner mange brukerinteraksjoner sted: klikk på knapper, skjemaer som fylles ut eller videoer som sees.
Hvis disse interaksjonene gir oss mulighet til å trekke konklusjoner om brukerengasjement, sendes de til f.eks. Google Analytics sammen med andre beskrivende data om den besøkende, økten, hendelsen i seg selv eller HTML-elementet de interagerte med.
Og dette er det avgjørende punktet: De ekstra dataene for å beskrive slike interaksjoner kommer fra forskjellige datakilder, for eksempel fra frontend, database eller en ekstern API.
For å forstå fordelene med et data lag, må vi først forstå utfordringene som oppstår når vi krever data fra flere datakilder.
La oss se på et eksempel der vi samler data fra slike kilder og tenke det gjennom:
Eksempel: Den besøkende kjøper et produkt på en nettside. Følgende dimensjoner kan være av interesse:
- produktnavn
- produktpris
- produktstørrelse
- produktkategori
- produktfarge
- handlekurvverdi
- merke
- første kjøp
- kundesegment
- kundens rabatt
- kjønn
- land
Etter kjøpet lander besøkende på en takk-side som viser alle detaljer om kjøpet og leveringsadressen.
Frontend: For å sende produktdata, handlekurvverdi og merke sammen med hendelsen, kan vi potensielt skrape det fra takk-siden.
Hovedutfordringen med å skrape data fra en webside er at dataene må være tilgjengelige på hver side der interaksjonen finner sted. Dette er sjelden tilfelle i virkeligheten.
Det er tilrådelig å måle så mange av de samme dimensjonene på tvers av alle interaksjoner på et nettsted for å gjøre interaksjonene sammenlignbare senere under dataanalysen. Derfor, hvis vi skulle følge denne tilnærmingen, er det sannsynlig at andre sider ikke viser produktdata, handlekurvverdi og merke for å sende sammen med andre hendelser.
Så hvis de nødvendige dataene ikke er tilgjengelige på andre sider, vil vi unngå å legge til alle disse dataene til innholdet bare for analytikkens skyld. Derfor bruker vi et data lag. Det gjør dataene tilgjengelige for oss å samle inn, uansett om de er synlige på siden eller ikke. Det er bokstavelig talt et lag med data som sitter på toppen av en hvilken som helst underside, og serverer de dataene vi trenger.
En annen utfordring med å skrape data fra frontend er at det til slutt bryter sammen. Når sider endres og disse endringene påvirker HTML-strukturen til de skrapede elementene, vil datainnsamlingen bryte sammen. Spesielt i større selskaper skjer det hyppige endringer på sider, og flere team jobber på dem uten å vite om noen HTML-elementer trengs for datainnsamling. Derfor vil enhver skraping av data fra frontend bryte på et tidspunkt på ofte oppdaterte nettsteder.
Et data lag utnytter denne tilnærmingen og gjør det mulig å hente brukerdata på en sikker og samtidig enkel måte.
Database: Å samle inn kundedata (kundesegment, rabatt, kjønn og første kjøp) kan bli litt utfordrende: Kundedata må enten sendes sammen med serverresponsen eller med en separat API.
Men siden dette er private data, må innsamlingen autentiseres av hensyn til databeskyttelse. Det betyr at en API-forespørsel ikke kan håndteres i nettleseren fordi API-nøkkelen ellers ville være tilgjengelig for erfarne brukere.
Derfor er den beste løsningen å sende dataene sammen med serverresponsen basert på nettstedets innloggingsautentisering.
Når brukeren er logget inn, fylles data laget med de relevante dataene fra databasen. Uten innlogging eksponeres ingen sensitive data.
API: Geo-data som landet kan hentes fra en ekstern tjeneste-API.
Imidlertid oppstår den samme utfordringen som ved henting av data fra databasen: Enhver API-forespørsel fra frontend eller tag management system krever en API-nøkkel, som ikke bør håndteres i nettleseren av sikkerhetsmessige årsaker.
En annen ulempe ved å bruke API-er for datainnsamling, spesielt med hendelser, er tiden det tar før dataene kommer tilbake. Hvis en bruker navigerer til en annen side før dataene ankom, risikerer vi å miste hendelsen.
La oss oppsummere fordelene raskt:
Fordeler
- Data er tilgjengelige uansett om de er synlige på siden
- Robust datainnsamling
- Sikker innsamling av sensitive data
- Reduserer datatap for asynkrone dataforespørsler
Hvorfor du sannsynligvis trenger et
Ved å opprette et data lag gjøres et JavaScript-objekt tilgjengelig i det globale området til nettleseren ved hver sideinnlasting.
Dataene det inneholder kan komme fra databasen din, frontend eller API-er, slik at datainnsamling fra disse kildene blir pålitelig, sikker og uavhengig av HTML-en på siden.
Data fra databasen kan gjøres tilgjengelige på enhver underside av nettstedet uten mye bryderi uten å være synlige i innholdet.
Av de ovennevnte årsakene råder jeg generelt klienter til å implementere data lag hvis de er seriøse om sine dataanalyseambisjoner. Fordelene med datakvalitet, pålitelighet og de relaterte langsiktige tidsbesparelsene rettferdiggjør de høyere implementeringskostnadene.
Det endelige målet med webanalyse er å ta datadrevne forretningsbeslutninger, så datakvalitet bør være en prioritet.
Nå, la oss se på de forskjellige tilgjengelige alternativene og noen implementeringseksempler før vi dykker ned i design- og implementeringsfasen.
Data Lag for Adobe Analytics, DTM, Launch og Tealium
Data lag kan ha forskjellige strukturer. Generelt skiller vi mellom de som kommer med en objektbasert struktur og en array-basert struktur.
Ifølge data lag definisjon fra World Wide Web Consortium (W3C) følger syntaksen den til et JavaScript-objekt. Det er uoffisielt forkortet CEDDL (Customer Experience Digital Data Layer).
Du kan også nestle andre objekter eller arrays i det:
window.digitalData = {pageName: "sneaker oversikt",destinationPath: "/no/sneakers",breadCrumbs: ["hjem","sneakers"],publishDate: "2020-07-01",language: "en-US"};
Adobe Analytics, Adobe Launch og Tealium følger CEDDL-strukturen. I eksempelet ovenfor lagrer vi data i et objekt kalt digitalData. Navnet er ikke standardisert og kan velges fritt, men du må erklære navnet i tag management systemet.
For å endre dataene er det flere alternativer (som med ethvert JS-objekt), men den enkleste måten er bare å overskrive verdiene:
window.digitalData.language = "de-DE";
Hovedideen med den objektbaserte strukturen er at de lastes inn én gang per sideinnlasting, men de endres ikke mye basert på brukerinteraksjon. Dataene er for det meste statisk.
Hendelsessporing er ikke drevet av hendelser som går inn i data lag-objektet. Hendelser spores med et separat sporingsbibliotek for å sende dem videre til en analyseplattform, f.eks. Adobe Analytics. Når hendelsessporingskoden kjøres, sendes data lag-objektet med i sin helhet og kan brukes under dataanalysen.
//Hendelse med valgt farge_satellite.setVar("sneaker farge", "svart");_satellite.track("velg farge");
Bruk Adobe Launch med en array-basert data lag
Du kan enkelt bruke Adobe Launch med en array-basert struktur også. Adobe Launch Extension Data Layer Manager gjør det mulig.
Her er noen lenker til flere ressurser for å bruke den array-baserte versjonen med Adobe Launch:
- Jim Gordon’s Demo av bruk av Data Layer Manager med Adobe Launch
- Data Layer Manager Extension med dokumentasjon
Data Lag for Google Tag Manager, Matomo og Piwik Pro
Data lag for Google Tag Manager, Matomo og Piwik Pro er array-basert og uoffisielt referert til som det hendelsesdrevne data laget (EDDL).
Data håndteres også i objekter, men den overordnede strukturen til GTM data laget er en array med objekter.
window.dataLayer = window.dataLayer || [{"pageCategory": "kategori side","pageName": "sneaker oversikt","language": "en-US",}];
Sporingslogikken med en array-basert struktur er forskjellig: Nye data eller endringer dyttes inn i det via dataLayer.push(). Så en push til data laget kan utløse taggutførelser i tag management systemet.
Den grunnleggende forskjellen til en objektbasert struktur er at endringer vanligvis sendes sammen med en hendelse og at regler utløses basert på disse endringene uten noe ekstra bibliotek, bare ved å observere om data lag-arrayen endres.
Siden ingen andre biblioteker som _satellite er nødvendig, krever vi en avhengighet mindre.
En annen karakteristikk ved den array-baserte tilnærmingen er at dataene endres ganske ofte gjennom brukerreisen siden enhver brukerinteraksjon kan endre data lag-variablene.
Så et array-basert data lag er grunnlaget for hendelsessporing og håndterer data mer fleksibelt, mens en objektbasert en heller fungerer som en statisk datalagring.
Gjennom den fleksibiliteten sies en array-basert data lag-struktur å være mer egnet for enkeltside-applikasjoner.
Du kan imidlertid også spore SPAer med et objektbasert data lag, det vil bare kreve noen flere linjer med kode og muligens noen kanttilfeller å løse.
Hvis du er i starten av et prosjekt og har valget, vil jeg foretrekke et array-basert data lag imidlertid.
Å endre en allerede eksisterende oppsett fra en objektstruktur til en array, er imidlertid unødvendig.
Innholdsstyringssystemer med data lag inkludert
WordPress-brukere har det enkelt siden de kan bruke denne pluginen for å implementere Google Tag Manager sammen med et forhåndskonfigurert data lag.
Det fylles automatisk med kategorier, forfatternavn, publiseringsdatoer og søkeord.
Datapunktene kan sjekkes eller avmerkes i plugin-innstillingene. Videre tilbyr pluginen forhåndskonfigurerte hendelser for skjemainnsendinger av de mest vanlige skjemapluginnene.
Hvis du er en nettbutikkeier og bruker WooCommerce for WordPress, kan du implementere et klassisk e-handelsdata lag samt et avansert e-handelsdata lag med samme plugin, som er ganske kraftig.
WordPress-brukere som ønsker å bruke Tealium kan bruke en plugin for Tealium.
Drupal har også en plugin.
Wix og Squarespace-brukere kan implementere Google Tag Manager gjennom plattformverktøyene, men må implementere data lag-koden manuelt.
Implementering av data lag
Så hvordan implementerer du et data lag? - Siden planlegging og implementering krever kunnskap på tvers av områdene digital analyse, frontend-utvikling og backend-utvikling, blir implementeringen vanligvis utført gjennom et webbyrå sammen med en analyse konsulent.
Analyse konsulenten briefer webbyrået og leder prosjektet til implementeringen er vellykket validert. Deretter konfigureres tag management systemet og analyseverktøyene.
Hvis du er interessert og kjenner litt til JavaScript, kan du implementere det selv med den følgendeimplementeringsveiledningen.
Implementeringen går gjennom 3 trinn:
1. Data Lag Design
Designfasen handler om å definere hvilke interaksjoner som skal måles sammen med hvilke dimensjoner.
Eventuelle attributter til besøkende, økter, sider, produkter eller hendelser kan være av potensiell interesse under data analyse og bør vurderes for data lag-arkitekturen.
For å bestemme hva som skal inkluderes, start med slutten i tankene og spør deg selv hvilke forretningskritiske spørsmål som må besvares og snevre inn på de relaterte datapunktene.
Neste steg er å finne ut hvordan disse datapunktene må struktureres og hvilke dimensjoner som er viktigst å legge til.
Eksempel: En språkskole som driver et WordPress-nettsted på flere språk ønsker å vite morsmålet til sine besøkende og hvilket fremmedspråk de er mest interessert i. Målet er å potensielt kjøre online annonsering via Facebook Ads som retter seg mot demografier med lignende attributter.
Som neste steg må vi definere alle relevante data på tvers av forskjellige typer sider (hjemmeside, kurs sider, om oss, kontakt og nyheter). For å forenkle, la oss se på de mest interessante sidene og fokusere på forsiden og kurssidene.

Eksempel: Array-basert Google Tag Manager data lag for en språkskole
window.dataLayer = window.dataLayer || [{"language": "de", //Språk for UI"sessionDuration": "182", //Øktvarighet i sekunder"languageIntent": "es", //mest besøkte kurs språk"pageType": "kurs side","courseName": "Spansk A1 - Nybegynner","courseLang": "es","courseLevel": "a1","courseDuration": "6" //Varighet i uker}];
Eksempel: Objektbasert data lag for Adobe Launch
window.digitalData = window.digitalData || {"language": "de", //Språk for UI"sessionDuration": 182, //Øktvarighet i sekunder"languageIntent": "es", //mest besøkte kurs språk"pageType": "kurs side","courseName": "Spansk A1 - Nybegynner","courseLang": "es","courseLevel": "a1","courseDuration": 6 //Varighet i uker};
2. Implementering
Data lag må implementeres på hver underside av et nettsted. Kodeeksemplene ovenfor viser imidlertid den endelige beregnede tilstanden.
Under implementeringen må datapunktene først hentes for å beregne deres endelige tilstand, så den faktiske kilden kommer til å se litt annerledes ut.
For å gi et realistisk eksempel antar jeg følgende:
- Øktvarighet og språkinteresse samles inn gjennom en egendefinert JavaScript og holdes i nettleserens lokale lagring.
- Språk, sidetype og kursdata kan hentes fra databasen via serverresponsen og gjøres tilgjengelig på kursskjemaene og forsiden.
Kildekoden til data laget i backend i henhold til de ovennevnte forutsetningene vil se slik ut:
window.dataLayer = window.dataLayer || [{"language": <?php echo wpb_getpagedata("lang"); ?>,"sessionDuration": window.localStorage.sessionDuration,"languageIntent": window.localStorage.languageIntent"pageType": <?php echo wpb_getpagedata("type"); ?>,"courseName": <?php echo wpb_getcoursedata("name"); ?>,"courseSprache": <?php echo wpb_getcoursedata("lang"); ?>,"courseLevel": <?php echo wpb_getcoursedata("level"); ?>,"courseDuration": <?php echo wpb_getcoursedata("duration"); ?>,}];
Hendelsessporing med data lag push
For å sende hendelser til et GTM data lag kan du bruke push-metoden og bokstavelig talt dytte hendelser inn i det.
window.dataLayer.push({"event": "course-booking","startWeek": "24"});
event nøkkelordet er et spesielt nøkkelord og kan adresseres som en egendefinert hendelse fra GTM containeren.
Tag management systemet observerer data laget og utfører en tag så snart en forhåndsdefinert egendefinert hendelse er sendt til det.
Etter at en hendelse er lagt til, kan TMS for eksempel sende en hendelse til Google Analytics.
Alle relevante data for å gi kontekst (navn, språk, språknivå, kursvarighet) er tilgjengelige og kan sendes sammen med hendelsen, for eksempel startuken for kurset.
I et objektbasert data lag vil den samme hendelsen bli sendt direkte til adobe analytics via deres eget hendelsessporingsbibliotek.
For Adobe Launch vil eksempel koden se slik ut:
_satellite.setVar("startWeek", 24);_satellite.track("course-booking");
Kodeplassering i kildekoden
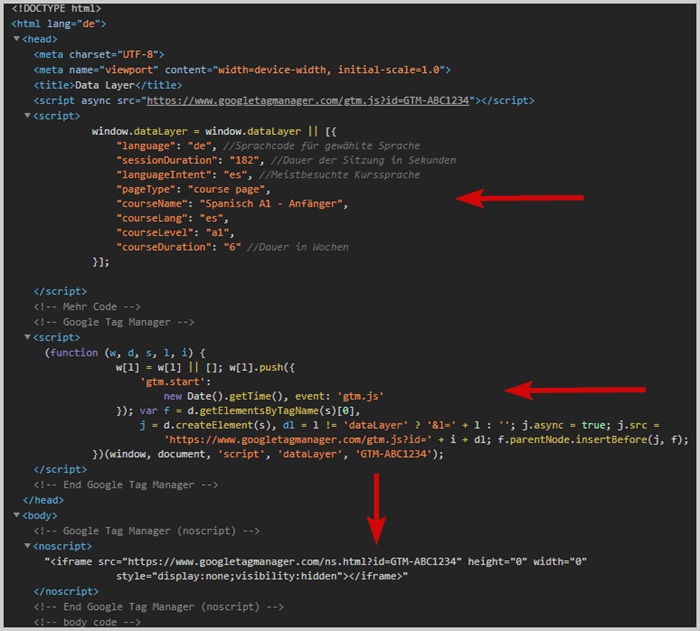
Data lag-koden bør legges til i <head> på siden før tag management systemet.
På grunn av denne rekkefølgen sikrer du at den allerede er beregnet når tag management systemet vil ha tilgang til den.
Eksempel: Plassering i kildekoden
3. Feilsøking
De vanligste prosedyrene for å feilsøke et data lag er å simulere sideinnlastinger eller hendelser for å verifisere at alle datapunktene fylles med de riktige dataene.
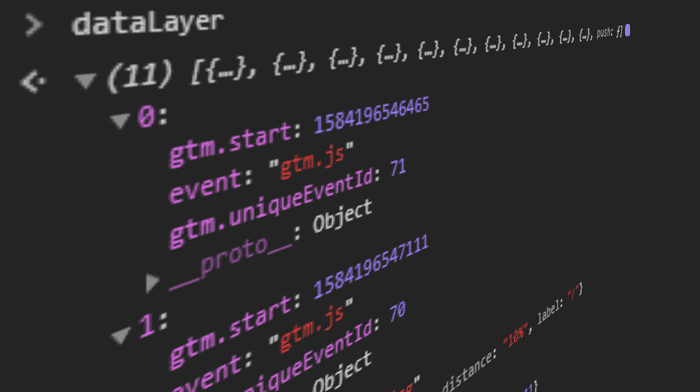
Siden det er globalt tilgjengelig i nettleserkonsollen, kan du enkelt skrive ut alle verdiene til konsollen (forutsatt at standard navnekonvensjoner er brukt):
Nettsteder med GTM
Object.assign(...dataLayer)
Nettsteder med Adobe Launch eller DTM
digitalData
Tealium
utag.data eller utag_data
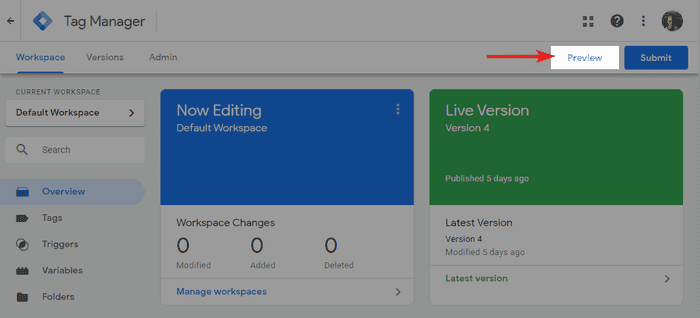
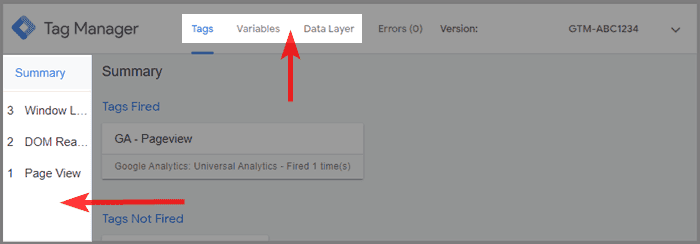
Google Tag Manager har til og med sin egen Debugger Mode. Du kan aktivere den fra GTM grensesnittet ved å klikke på preview øverst til høyre.
Hvis du ikke har tilgang til tag management containeren, men vil feilsøke det likevel, kan du bruke en chrome extension.
Data Lag Chrome Extensions
Det finnes en rekke potensielle utvidelser for feilsøking der ute. Jeg foretrekker de som støtter de fleste leverandører, så jeg ikke trenger å bytte mellom utvidelser når jeg feilsøker et annet nettsted.
Følgende chrome-utvidelser er for øyeblikket mine favoritter for feilsøking:
- Trackie - Utvidelse basert på Data Slayer og open source. Den har ganske god ytelse og støtter GTM, DTM, Tealium og mange flere.
- Omnibug - En annen allrounder med støtte for Adobe Analytics (DTM & Launch), samt Matomo, GTM, Tealium og mer.
Chrome-utvidelser for feilsøking av Google Analytics og GTM
- GTM/GA Debug - etter å ha aktivert utvidelsen vil det være en ny fane tilgjengelig i Chrome DevTools når du åpner dem (F12 på Windows og CTRL+SHIFT+i på Mac). Alle relevante data vises i en grafisk UI og den oppdateres mens du surfer på et nettsted.
- Adswerve - dataLayer Inspector+ - logger alle relevante datapunkter til nettleserkonsollen. Aktiver "preserve log" i konsollinnstillingene, for å beholde logger på tvers av sidenavigasjon.
- Data Slayer - definitivt utvidelsen med det kuleste navnet og logoen og min tidligere favoritt. Det er open source med et enkelt oppsett og fungerer også med Adobe DTM.
Fjern avmerkingen for “use three-column layout where available”, “show GA Classic tags” og “show Floodlight tags” i utvidelsesinnstillingene, ellers blir loggene litt rotete.
Chrome-utvidelser for feilsøking av Adobe Analytics, Launch og DTM
- Launch & DTM Switch - lar deg laste staging- eller produksjonsbiblioteket til tag management systemet og kan aktivere feilsøkingsmodus.
- Debugger for Adobe Analytics - aktiverer feilsøkingsmodus. Alternativt kan du også skrive
_satellite.setDebug(true)inn i konsollen. - Adobe Experience Cloud Debugger - meta utvidelse for å feilsøke alle Adobe-produkter.
- Adobe Experience Platform Debugger - etterfølgeren til Experience Cloud Debugger som tilbyr bedre oversikt (for øyeblikket fortsatt i beta).
- Tealium Data Layer Debugger - enkle tabeller med alle gjeldende verdier.
E-handel Data Lag
Data lag for e-handel er mer omfattende og deres struktur er mer kompleks. De må inneholde mer data og håndtere flere hendelser.
Det er derfor planlegging og implementering av et e-handelsnettsted tar betydelig mer tid.
E-handelsrapporten i Google Analytics, for eksempel, viser ingen data hvis implementeringen ikke følger deres e-handelsdata lag dokumentasjon.
Store e-handelsbutikker krever imidlertid enda mer avanserte sporingsoppsett. De implementerer et data lag for avansert e-handel, som muliggjør enda mer funksjonalitet i Google Analytics.
Du må følge implementeringsretningslinjene for Google Analytics nøye for at e-handelsrapportene skal fungere. Det gjelder strukturen til data laget og også variabelnavn.
Hvis du velger en annen analyseplattform for e-handel, står du fritt til å planlegge strukturen som du vil.
Når er et data lag ikke nødvendig?
Som med alt annet, er det også tilfeller der den ekstra innsatsen for å implementere et data lag ikke er berettiget.
I eksemplene ovenfor så vi på tilfeller der vi hentet data fra forskjellige datakilder (Frontend, Backend, API) og løste problemer som oppsto ved å jobbe med en rekke datakilder.
Mange nettsteder (såkalte brosjyre-nettsteder) har imidlertid verken en innloggingsfunksjon eller en database.
En annen viktig faktor er hvor ofte endringer implementeres på nettstedet. Mange nettsteder sjelden gjennomgår innholdet sitt eller legger til funksjonalitet regelmessig. Jeg ser til og med at bedrifter driver enkle brosjyre-nettsteder med omtrent 50 undersider og et kontaktskjema som den vanskeligste konverteringen.
Siden slike nettsteder sannsynligvis bare krever data fra frontend for å gjøre sin dataanalyse, kan de klare seg med et enkelt analyseoppsett uten noe data lag. Det vil ikke gjøre innsamlingsdelen mye mer robust eller sikrere, og dermed reduseres fordelene. Under slike omstendigheter rettferdiggjør ikke fordelene den ekstra innsatsen ved implementering.
Typiske eksempler på når et data lag ikke er nødvendig, er brosjyresider eller innholdssider med et begrenset antall eller nesten ingen harde konverteringer. Vanligvis er slike eiere av nettsteder bare interessert i å kategorisere brukerengasjementet etter deres innholdseksjoner eller noen interne bedriftsklassifikasjoner.
Slike krav kan oppnås med litt avansert JavaScript og et gjennomtenkt system for strukturering av innholdet.
Så snart datainnsamlingen fra frontend regelmessig bryter sammen og definitivt når en database skal involveres, anbefales et data lag.
Alternative løsninger er ofte bare midlertidig tilfredsstillende, på grunn av stadig økende analyseambisjoner og regelmessig sammenbrudd av datainnsamlingen. I tillegg er alle tilpassede løsninger vanligvis vanskelige å overlevere til et annet byrå.
Et data lag har gode sjanser til å overleve tidens prøve fordi det allerede er et etablert konsept i webanalysebransjen, så webbyråer har økende erfaring med å implementere og vedlikeholde et.
Konklusjon
Et data lag er gullstandarden for profesjonelle analyseoppsett. Det øker datakvaliteten og dermed forbedrer dataanalysen som helhet, samtidig som det oppfyller sikkerhetskrav.
For ambisiøse nettstedseiere som ønsker å begynne med seriøs dataanalyse, er det den enkleste og mest robuste løsningen.
Hvis du har valget, implementer en array-basert struktur, siden du har færre avhengigheter og kan bruke den på alle typer nettsteder.
Innholdssider er imidlertid så begrenset i funksjonalitet og vanligvis bare med et begrenset antall harde konverteringer, så et data lag kan potensielt neglisjeres. Dette gjelder spesielt hvis alle nødvendige data er tilgjengelige på sidene eller kan gjøres tilgjengelige gjennom noen omveier.
Hvis du vil implementere et selv, er det sannsynligvis enklest å gjøre det med et WordPress-nettsted. Eventuelle avanserte krav er imidlertid sannsynligvis ikke verdt tiden og risikoen for et utilfredsstillende resultat.
Derfor er det vanligvis veien å gå å implementere med hjelp av en analyse konsulent, siden det sparer tid og unngår unødvendige risikoer.
Jeg anbefaler deg å installere en av de nevnte chrome-utvidelsene for å inspisere data lagene til noen større nettsteder der ute. Det er vanligvis en stor inspirasjon og gir noen interessante KPIer å potensielt integrere i dine egne analyseoppsett 😉.
Data Lag dokumentasjon fra forskjellige TMS-leverandører
- Google Tag Manager: Initiering og endring av data
- Adobe Launch: Initiering
- Tealium iQ: Initiering og endring av data
- Matomo: Initiering og endring av data
- Piwik Pro: Initiering og endring av data
FAQ
Hva er et data lag eksempel?
Et data lag eksempel er gitt i artikkelen. Et JavaScript-objekt lagrer data fra en nettside, database eller en ekstern kilde på en sentral, fleksibel og lett tilgjengelig måte. Et eksempel på kode for å initiere et data lag for Google Tag Manager er: window.dataLayer = window.dataLayer || [{ "pageCategory": "kategori side", "pageName": "sneaker oversikt", "language": "en-US",}];
Hva er data lag variabler?
Data lag variabler er nøkkel-verdi-par innenfor data laget som lagrer spesifikke informasjonsbiter. Disse variablene kan inkludere sideegenskaper, brukeradferdsdata og mer, og tjener som et sentralt dataregister for analyse og sporing.
Hvorfor bruke et data lag?
Et data lag er essensielt for robust, fleksibel og sikker datainnsamling. Det sentraliserer data fra forskjellige kilder, gjør det lett tilgjengelig og konsistent på tvers av ulike websider og brukerinteraksjoner. Denne tilnærmingen forbedrer datakvalitet og pålitelighet, som er avgjørende for datadrevne beslutninger.
Trenger jeg et data lag?
Selv om det ikke alltid er nødvendig, anbefales et data lag generelt for de som er seriøse med sine dataanalyseambisjoner. Det gir datakvalitet, pålitelighet og langsiktige tidsbesparelser som rettferdiggjør den høyere implementeringsinnsatsen.
Hva er fordelene med et data lag?
Fordelene med et data lag inkluderer: Tilgjengelighet av data uavhengig av om det er synlig på siden. Robust datainnsamling. Redusering av datatap for asynkrone dataforespørsler. Sikker datainnsamling fra flere kilder.
Har alle nettsteder et data lag?
Ikke alle nettsteder har et data lag. Implementeringen avhenger av kompleksiteten til nettstedet og dybden av dataanalysen som kreves. Enkle nettsteder har kanskje ikke et data lag, mens mer komplekse nettsteder, spesielt de som fokuserer på datadrevne beslutninger, sannsynligvis vil ha det.
Hvordan får jeg tilgang til data laget?
Data laget er globalt tilgjengelig i nettleserkonsollen. For nettsteder med Google Tag Manager kan du få tilgang til det ved å bruke dataLayer eller Object.assign(...dataLayer). For Adobe Launch eller DTM kan du få tilgang til det ved å bruke digitalData.
Hvordan dyttes data inn i data laget?
For å dytte data inn i data laget, bruker du dataLayer.push() metoden. For eksempel: window.dataLayer.push({ "event": "course-booking", "startWeek": "24" }); Denne metoden brukes til å legge til nye data eller endringer i data laget. Event-nøkkelordet kan brukes til å utløse en annen tag utførelse i tag management systemet.
Ytterligere ressurser
- Simo Ahava om data laget i GTM og hvordan håndtere data i det.
- Les min Google Tag Manager veiledning og lær hvordan du setter det opp.
- Kevin Haags presentasjon fra Measurecamp Berlin 2019 om Event Driven Data Layer i Adobe Analytics