Data Lager
I samband med tagghantering och webbanalys har du kanske hört termen data-lager. Det är den grundläggande elementet i en ambitiös webbanalysuppsättning eftersom alla datapunkter och spårningsregler är beroende av det.
Därför behandlas det som ett icke-förhandlingsbart krav för alla analysuppsättningar i den digitala analysvärlden. Dock finns det scenarier där det inte är nödvändigt.
Därför vill jag förklara vad ett data-lager är, dess fördelar, och skillnaderna mellan data-lager för Google Tag Manager och Adobe Launch.
Därefter kommer vi att titta på implementeringen för de mest populära Tag Management Systems (TMS). Jag kommer att förklara designfasen, följt av implementeringen och felsökning.
Vad är ett data-lager?
Ett data-lager är en datastruktur som tillhandahåller relevant information i nyckel-värde-par för användning med till exempel Tag Management Systems.
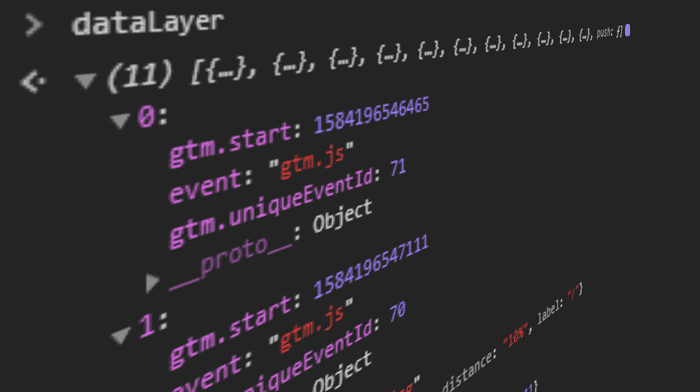
Ett data-lager är tillgängligt i det globala JavaScript-området på webbplatsen som en array eller objekt och håller data i en strukturerad form för andra program att använda.
Fördelen med ett data-lager ligger i ett programmässigt enkelt tillgång till relevant data under ett webbplatsbesök.
Det möjliggör tillgång till data på en central punkt och är grunden för dataanalyslogiken i ett tagghanteringssystem.
window.dataLayer = window.dataLayer || [{"pageCategory": "kategorisida","pageName": "sneaker översikt","language": "sv-SE",}];
Eftersom det används för att lagra data från flera datakällor, förenklar det övervakningen av aktuella datavärden, eftersom endast en enda plats behöver observeras ("single point of truth").
Ett data-lager återskapas vid varje sidladdning utrustat med datapunkter på den aktuella webbsidan och eventuellt annan relaterad data om besökaren och dess besök.
Notera: Ensidiga applikationer (SPA) laddar inte om sidan mellan sidnavigeringen. Det är därför konfigurationen av data-lagret för en ensidig applikation är annorlunda än för typiska webbsidor med sidladdningar.
Den hållna datan representerar egenskaper eller funktioner hos en undersida och hålls i ett nyckel-värde-par. Nycklarna håller beskrivande namn på funktionerna parat med ett aktuellt värde, som vanligtvis ändras under användarens resa.
window.dataLayer = window.dataLayer || [{"pageCategory": "kategorisida", //kategori"pageName": "sneaker översikt", //namn"language": "se-SE", //språk}];
Det övergripande målet är att göra dessa datapunkter tillgängliga i tagghanteringssystemet, så att de kan skickas tillsammans med data som delas med t.ex. Google Analytics eller Facebook Ads för att bättre beskriva webbplatsinteraktioner.
För att möjliggöra denna integration, håller TMS referenser till nyckel-värde-par och kan till exempel utföra regler när deras värde ändras.
Exempel: En besökare zoomar in på en produktbild och därmed utlöser en händelse "produktzoom". Utan ytterligare data som skickas tillsammans med händelsen är det inte särskilt insiktsfullt. Därför skickar vi också data om t.ex. produktnamn, kategori och pris, så att vi kan analysera händelsen i ett meningsfullt sammanhang.
Den ytterligare datan skulle göra det möjligt att verifiera om sådana produktzoomar endast förekommer i vissa produktkategorier. Om så är fallet, kan det vara fördelaktigt att lägga till fler bilder till andra produkter i samma kategori, eftersom besökare verkar vara mycket intresserade av bilddetaljerna för dessa produkter.
Slutsatsen är att vi strukturerar all relevant data i beskrivande nycklar och värden och gör dem tillgängliga på en central plats där de enkelt kan hämtas.
Sådana datapunkter är vanligtvis viktiga egenskaper hos sidinnehållet eller någon klassificering vi kommit på för att segmentera besökare baserat på beteende.
För att bättre förstå vad ett data-lager är, som en förenklad visualisering, kan du tänka dig ett Excel-ark. Arket håller viktiga egenskaper om en webbsida i sin rubrik (sökväg, språk, kategori, inloggningsstatus) tillsammans med ett aktuellt värde för varje post.

Vad är fördelarna med att använda ett data-lager?
När en besökare navigerar genom en webbplats sker många användarinteraktioner: klick på knappar, formulär som fylls i eller tittade videor.
Om dessa interaktioner tillåter oss att dra slutsatser om användarengagemang, skickas de till t.ex. Google Analytics tillsammans med annan beskrivande data om besökaren, sessionen, själva händelsen eller HTML-elementet de interagerade med.
Och detta är den avgörande punkten: Den ytterligare data som beskriver sådana interaktioner kommer från olika datakällor, till exempel från frontend, databasen eller en extern API.
För att förstå fördelarna med ett data-lager, måste vi först förstå de utmaningar som uppstår när vi behöver data från flera datakällor.
Låt oss titta på ett exempel där vi samlar in data från sådana källor och tänka igenom det:
Exempel: Besökaren köper en produkt på en webbplats. Följande dimensioner kan vara av intresse:
- produktnamn
- produktpris
- produktstorlek
- produktkategori
- produktfärg
- kundvagnsvärde
- varumärke
- första köp
- kundsegment
- kundrabatt
- kön
- land
Efter köpet landar besökare på en tack-sida som listar alla detaljer om köpet och leveransadressen.
Frontend: För att skicka produktdata, kundvagnsvärde och varumärke tillsammans med händelsen, kan vi potentiellt skrapa det från tack-sidan.
Den största utmaningen med att skrapa data från en webbsida är att datan måste vara tillgänglig på varje sida där interaktionen äger rum. Detta är sällan fallet i verkligheten.
Det är lämpligt att mäta så många av samma dimensioner över alla interaktioner på en webbplats för att göra interaktionerna jämförbara senare under dataanalysen. Därför, om vi skulle följa den metoden, är det troligt att andra sidor inte listar produktdata, kundvagnsvärde och varumärke att skicka tillsammans med andra händelser.
Så om den nödvändiga datan inte är tillgänglig på andra sidor, vill vi undvika att lägga till all den datan till innehållet bara för analysens skull. Därför använder vi ett data-lager. Det gör datan tillgänglig för oss att samla in, oavsett om den är synlig på sidan eller inte. Det är bokstavligen ett lager av data som ligger ovanpå varje given undersida och tillhandahåller den data vi behöver.
En annan utmaning med att skrapa data från frontend är att det till slut bryter. När sidor ändras och dessa ändringar påverkar HTML-strukturen på de skrapade elementen, då kommer datainsamlingen att bryta. Speciellt i större företag sker frekventa ändringar på sidor och flera team arbetar på dem utan att veta om vissa HTML-element behövs för datainsamling. Därför kommer all skrapning av data från frontend att bryta vid någon tidpunkt på ofta uppdaterade webbplatser.
Ett data-lager utnyttjar detta tillvägagångssätt och gör det möjligt att hämta användardata på ett säkert och ändå enkelt sätt.
Databas: Att samla in kunddata (kundsegment, rabatt, kön och första köp) kan bli lite krångligt: Kunddata skulle antingen behöva skickas tillsammans med serverresponsen eller med ett separat API.
Men eftersom detta är privata data, måste insamlingen vara autentiserad för dataskyddssyften. Det innebär att en API-begäran inte kunde hanteras i webbläsaren eftersom API-nyckeln annars skulle vara tillgänglig för erfarna användare.
Därför är den bästa lösningen att skicka datan tillsammans med serverresponsen baserat på webbplatsens inloggningsautentisering.
När användaren är inloggad, fylls data-lagret med relevant data från databasen. Utan inloggning exponeras ingen känslig data.
API: Geodata som landet kan hämtas från en extern tjänst-API.
Dock uppstår samma utmaning som vid hämtning av data från databasen: Alla API-begäranden från frontend eller tagghanteringssystemet kräver en API-nyckel, som inte bör hanteras i webbläsaren av säkerhetsskäl.
En annan nackdel med att arbeta med API:er för datainsamling, särskilt med händelser, är tiden tills datan kommer tillbaka. Om en användare navigerar till en annan sida innan datan har anlänt, riskerar vi att förlora händelsen.
Låt oss sammanfatta fördelarna snabbt:
Fördelar
- Data är tillgänglig oavsett om den är synlig på sidan eller inte
- Robust datainsamling
- Säker insamling av känslig data
- Förhindrar dataförlust vid asynkrona databehov
Varför du förmodligen behöver en
Genom att skapa ett data-lager görs ett JavaScript-objekt tillgängligt i det globala området i webbläsaren vid varje sidladdning.
Datan det innehåller kan härledas från din databas, frontend eller API:er, så datainsamling från dessa källor blir pålitlig, säker och oberoende av HTML på sidan.
Data från databasen kan göras tillgänglig på vilken undersida som helst av webbplatsen utan större besvär utan att vara synlig i innehållet.
Av ovanstående skäl råder jag generellt kunder att implementera data-lager om de är seriösa med sina dataanalysambitioner. Fördelarna med datakvalitet, pålitlighet och de relaterade långsiktiga tidsbesparingarna rättfärdigar de högre implementeringsinsatserna.
Det ultimata målet med webbanalys är att fatta datadrivna affärsbeslut, så datakvalitet bör vara en prioritet.
Låt oss nu titta på de olika alternativen som finns och några implementeringsexempel innan vi dyker in i design- och implementeringsfasen.
Data-lager för Adobe Analytics, DTM, Launch och Tealium
Data-lager kan ha olika strukturer. Generellt skiljer vi mellan de som kommer med en objektbaserad struktur och en array-baserad struktur.
Enligt definitionen av data-lagret från World Wide Web Consortium (W3C) följer syntaxen den för ett JavaScript-objekt. Det förkortas inofficiellt CEDDL (Customer Experience Digital Data Layer).
Du kan också nästla andra objekt eller arrayer i det:
window.digitalData = {pageName: "sneaker översikt",destinationPath: "/se/sneakers",breadCrumbs: ["hem","sneakers"],publishDate: "2020-07-01",language: "se-SE"};
Adobe Analytics, Adobe Launch och Tealium följer CEDDL-strukturen. I exemplet ovan lagrar vi data i ett objekt som heter digitalData. Namnet är inte standardiserat och kan väljas fritt, men du måste deklarera namnet i tagghanteringssystemet.
För att ändra datan finns det flera alternativ (som med vilket JS-objekt som helst), men det enklaste sättet är att bara skriva över värdena:
window.digitalData.language = "de-DE";
Den centrala idén med den objektbaserade strukturen är att de laddas en gång per sidladdning, men de ändras inte mycket baserat på användarinteraktion. Datan är mestadels statisk.
Händelsespårning drivs inte av händelser som kommer in i data-lager-objektet. Händelser spåras med ett separat spårningsbibliotek för att skicka dem vidare till en analysplattform t.ex. Adobe Analytics. När händelsespårningskoden körs skickas data-lager-objektet med i sin helhet och kan användas under dataanalysen.
//Händelse med vald färg_satellite.setVar("sneaker color", "black");_satellite.track("select color");
Använd Adobe Launch med ett array-baserat data-lager
Du kan enkelt använda Adobe Launch med en array-baserad struktur också. Adobe Launch Extension Data Layer Manager gör det möjligt.
Här är några länkar till ytterligare resurser för att använda den array-baserade versionen med Adobe Launch:
- Jim Gordons Demo av att använda Data Layer Manager med Adobe Launch
- Data Layer Manager Extension med dokumentation
Data-lager för Google Tag Manager, Matomo och Piwik Pro
Data-lagret för Google Tag Manager, Matomo och Piwik Pro är array-baserat och inofficiellt refererat till som det händelsedrivna data-lagret (EDDL).
Data hanteras också i objekt, men den övergripande strukturen för GTM-data-lagret är en array med objekt.
window.dataLayer = window.dataLayer || [{"pageCategory": "kategorisida","pageName": "sneaker översikt","language": "sv-SE",}];
Spårningslogiken med en array-baserad struktur är annorlunda: Ny data eller ändringar skjuts in i den via dataLayer.push(). Så en push till data-lagret kan sedan utlösa taggexekveringar i tagghanteringssystemet.
Den grundläggande skillnaden mot en objektbaserad struktur är att ändringar vanligtvis skickas tillsammans med en händelse och att regler utlöses baserat på dessa ändringar utan något ytterligare bibliotek, bara genom att observera om data-lager-arrayen ändras.
Eftersom inget annat bibliotek som _satellite är nödvändigt, behöver vi en beroende mindre.
En annan egenskap hos det array-baserade tillvägagångssättet är att datan ändras ganska ofta under användarens resa eftersom alla användarinteraktioner kan ändra data-lagervariablerna.
Så ett array-baserat data-lager är grunden för händelsespårning och hanterar data mer flexibelt medan ett objektbaserat snarare fungerar som ett statiskt datalager.
Genom den flexibiliteten anses en array-baserad data-lager-struktur vara mer lämplig för Single-Page-Applications.
Du kan dock även spåra SPA:er med ett objektbaserat data-lager, det kommer bara att kräva några fler rader kod och potentiellt några edge cases att lösa.
Om du är i början av ett projekt och har valet, skulle jag föredra ett array-baserat data-lager dock.
Att ändra en redan befintlig uppsättning från en objektstruktur till en array är dock onödigt.
Content Management Systems med data-lager inkluderat
WordPress användare har det enkelt eftersom de kan använda detta plugin för att implementera Google Tag Manager tillsammans med ett förkonfigurerat data-lager.
Det fylls automatiskt med kategorier, författarnamn, publiceringsdatum och söktermer.
Datapunkterna kan kontrolleras eller avmarkeras i plugin-inställningarna. Dessutom erbjuder pluginet förkonfigurerade händelser för formulärinlämningar av de vanligaste formulärpluginsen.
Om du är en webshop-ägare och använder WooCommerce för WordPress, kan du implementera ett klassiskt e-handels data-lager såväl som ett förbättrat e-handels data-lager med samma plugin, vilket är ganska kraftfullt.
WordPress användare som vill använda Tealium kan använda ett plugin för Tealium.
Drupal har också ett plugin.
Wix och Squarespace användare kan implementera Google Tag Manager genom plattformverktygen men måste implementera data-lagerkoden manuellt.
Data-lager implementering
Så hur implementerar man ett data-lager? - Eftersom planering och implementering kräver kunskap inom områdena digital analys, frontend-utveckling och backend-utveckling, utförs implementeringen vanligtvis genom en webbyrå tillsammans med en analyskonsult.
Analyskonsulten instruerar webbyrån och leder projektet tills implementeringen är framgångsrikt validerad. Därefter konfigureras tagghanteringssystemet och analysverktygen.
Om du är intresserad och kan lite JavaScript kan du implementera det själv med följandeimplementeringsguide.
Implementeringen går igenom 3 steg:
1. Data Layer Design
Designfasen handlar om att definiera vilka interaktioner som ska mätas tillsammans med vilka dimensioner.
Alla attribut för besökaren, sessionen, sidan, produkten eller händelsen kan vara av potentiellt intresse under dataanalysen och bör beaktas för data-lager-arkitekturen.
För att bestämma vad som ska inkluderas, börja med slutet i åtanke och fråga dig själv vilka affärskritiska frågor som behöver besvaras och fokusera på de relaterade datapunkterna.
Nästa steg är att ta reda på hur dessa datapunkter måste struktureras och vilka dimensioner som är viktigast att lägga till.
Exempel: En språkskola som driver en WordPress-webbplats på flera språk vill veta modersmålet för sina webbplatsbesökare och vilket främmande språk de är mest intresserade av. Målet är att eventuellt köra onlineannonsering via Facebook Ads som riktar sig till demografiska grupper med liknande attribut.
Som nästa steg skulle vi behöva definiera all relevant data över olika typer av sidor (hemsida, kurssidor, om oss, kontakt och nyheter). För att förenkla, låt oss titta på de mest intressanta sidorna och fokusera på startsidan och kurssidorna.

Exempel: Array-baserat Google Tag Manager data-lager för en språkskola
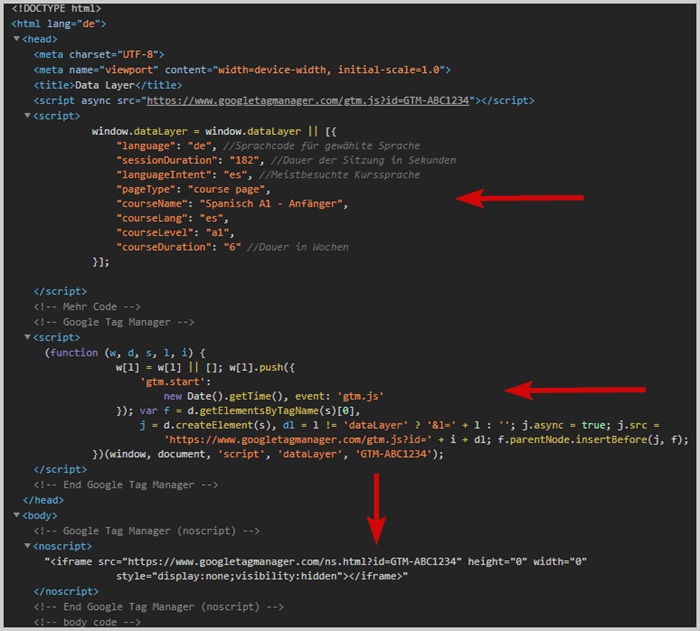
window.dataLayer = window.dataLayer || [{"language": "de", //Språk för UI"sessionDuration": "182", //Sessionslängd i sek"languageIntent": "es", //mest besökta kursspråk"pageType": "kurssida","courseName": "Spanska A1 - Nybörjare","courseLang": "es","courseLevel": "a1","courseDuration": "6" //Längd i veckor}];
Exempel: Objektbaserat data-lager för Adobe Launch
window.digitalData = window.digitalData || {"language": "de", //Språk för UI"sessionDuration": 182, //Sessionslängd i sek"languageIntent": "es", //mest besökta kursspråk"pageType": "kurssida","courseName": "Spanska A1 - Nybörjare","courseLang": "es","courseLevel": "a1","courseDuration": 6 //Längd i veckor};
2. Implementering
Data-lager måste implementeras på varje undersida av en webbplats. Kodeexemplen ovan visar dock det slutliga beräknade tillståndet.
Under implementeringen måste datapunkterna först hämtas för att beräknas till sitt slutliga tillstånd, så den faktiska källan kommer att se något annorlunda ut.
För att ge ett realistiskt exempel antar jag följande:
- Sessionslängd och språkintresse samlas in via en egenutvecklad JavaScript och hålls i webbläsarens lokala lagring.
- Språk, sidtyp och kursdata kan hämtas från databasen via serverresponsen och göras tillgängliga på kurssidorna och startsidan.
Källkoden för data-lagret i backend enligt ovanstående premisser skulle se ut så här:
window.dataLayer = window.dataLayer || [{"language": <?php echo wpb_getpagedata("lang"); ?>,"sessionDuration": window.localStorage.sessionDuration,"languageIntent": window.localStorage.languageIntent"pageType": <?php echo wpb_getpagedata("type"); ?>,"courseName": <?php echo wpb_getcoursedata("name"); ?>,"courseSprache": <?php echo wpb_getcoursedata("lang"); ?>,"courseLevel": <?php echo wpb_getcoursedata("level"); ?>,"courseDuration": <?php echo wpb_getcoursedata("duration"); ?>,}];
Händelsespårning med data layer push
För att skicka händelser till ett GTM data-lager kan du använda dess push-metod och bokstavligen trycka in händelser i det.
window.dataLayer.push({"event": "course-booking","startWeek": "24"});
Nyckelordet event är ett speciellt nyckelord och kan adresseras som en custom event från GTM-behållaren.
Tagghanteringssystemet observerar data-lagret och kör en tagg så snart en fördefinierad custom event skickas till det.
Efter att en händelse har lagts till kan TMS till exempel skicka en händelse till Google Analytics.
All relevant data för att ge kontext (namn, språk, språknivå, kurslängd) är tillgänglig och kan skickas tillsammans med händelsen, till exempel startveckan för kursen.
I ett objektbaserat data-lager skulle samma händelse skickas direkt till Adobe Analytics via deras eget händelsespårningsbibliotek.
För Adobe Launch skulle exempel koden se ut så här:
_satellite.setVar("startWeek", 24);_satellite.track("course-booking");
Kodpositionering i källkoden
Data-lagerkoden bör läggas till i <head> på sidan före tagghanteringssystemet.
På grund av denna ordning säkerställer du att den redan är beräknad när tagghanteringssystemet vill komma åt den.
Exempel: Positionering i källkoden
3. Felsökning
De vanligaste procedurerna för att felsöka ett data-lager är att simulera sidladdningar eller händelser för att verifiera att alla datapunkter fylls med korrekt data.
Eftersom det är globalt tillgängligt i webbläsarkonsolen kan du enkelt skriva ut alla värden till konsolen (förutsatt att standardnamngivningskonventioner tillämpas):
Webbplatser med GTM
Object.assign(...dataLayer)
Webbplatser med Adobe Launch eller DTM
digitalData
Tealium
utag.data eller utag_data
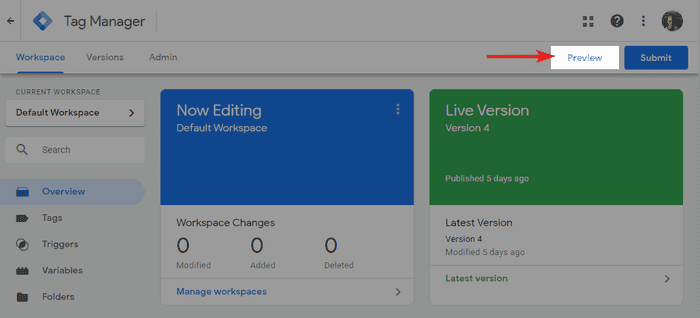
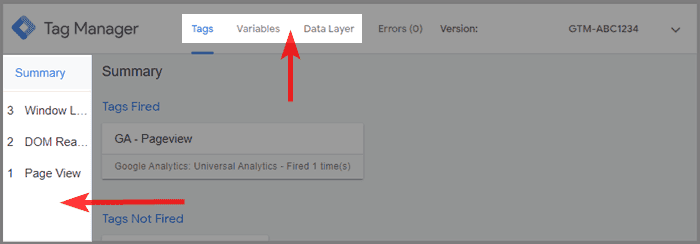
Google Tag Manager har till och med sitt eget Debugger Mode. Du kan aktivera det från GTM gränssnittet genom att klicka på förhandsgranska uppe till höger.
Om du inte har tillgång till tagghanteringsbehållaren men ändå vill felsöka den, kan du använda en chrome extension.
Data Layer Chrome Extensions
Det finns en mängd potentiella tillägg för felsökning där ute. Jag föredrar de som stöder de flesta leverantörer, så jag inte behöver byta mellan tillägg när jag felsöker en annan webbplats.
Följande chrome extensions är för närvarande mina favoriter för felsökning:
- Trackie - Tillägg baserat på Data Slayer och open source. Det har ganska bra prestanda och stöder GTM, DTM, Tealium och många fler.
- Omnibug - En annan all-rounder med stöd för Adobe Analytics (DTM & Launch), samt Matomo, GTM, Tealium och fler.
Chrome Extensions för felsökning av Google Analytics och GTM
- GTM/GA Debug - efter att ha aktiverat tillägget kommer det att finnas en ny flik tillgänglig i Chrome DevTools när du öppnar dem (F12 på Windows och CTRL+SHIFT+i på Mac). All relevant data visas i ett grafiskt gränssnitt och uppdateras medan du surfar på en webbplats.
- Adswerve - dataLayer Inspector+ - loggar alla relevanta datapunkter i webbläsarkonsolen. Aktivera "preserve log" i konsolinställningarna för att behålla loggar över sidnavigering.
- Data Slayer - definitivt tillägget med det coolaste namnet och logotypen och min tidigare favorit. Det är open source med en enkel layout och fungerar även med Adobe DTM.
Avmarkera “use three-column layout where available”, “show GA Classic tags” och “show Floodlight tags” i tilläggsinställningarna, annars blir loggarna lite röriga.
Chrome Extensions för felsökning av Adobe Analytics, Launch och DTM
- Launch & DTM Switch - låter dig ladda staging- eller produktionsbiblioteket för tagghanteringssystemet och kan aktivera felsökningsläget.
- Debugger for Adobe Analytics - aktiverar felsökningsläget. Alternativt kan du också skriva
_satellite.setDebug(true)i konsolen. - Adobe Experience Cloud Debugger - meta-extension för att felsöka alla Adobe-produkter.
- Adobe Experience Platform Debugger - efterföljaren till experience cloud debugger som erbjuder en bättre översikt (för närvarande fortfarande i beta).
- Tealium Data Layer Debugger - enkla tabeller över alla aktuella värden.
E-handels Data Layer
Data-lager för e-handel är mer omfattande och deras struktur är mer komplex. De måste hålla mer data och hantera fler händelser.
Därför tar planering och implementering av en e-handelswebbplats betydligt mer tid.
E-handelsrapporten i Google Analytics, till exempel, visar inga data om implementeringen inte följer deras dokumentation för e-handels data layer.
Stora e-handelsbutiker kräver dock ännu mer avancerade spårningsinställningar. De implementerar ett data layer för förbättrad e-handel, vilket möjliggör ännu mer funktionalitet i Google Analytics.
Du måste strikt följa implementeringsriktlinjerna för Google Analytics för att e-handelsrapporterna ska fungera. Det gäller data layer-strukturen och även variabelnamn.
Om du väljer en annan analysplattform för e-handel, är du fri att planera strukturen som du vill.
När är ett data layer inte nödvändigt?
Som med allt, finns det också fall där den extra ansträngningen att implementera ett data layer inte är motiverad.
I exemplen ovan tittade vi på fall där vi hämtade data från olika datakällor (Frontend, Backend, API) och löste problem som uppstod när vi arbetade med en mängd olika datakällor.
Många webbplatser (så kallade broschyr-webbplatser) har dock inte ens en inloggningsfunktion eller en databas.
En annan viktig faktor är hur ofta ändringar implementeras på webbplatsen. Många webbplatser granskar sällan sitt innehåll eller lägger till funktionalitet regelbundet. Jag ser till och med företag som driver enkla broschyr-webbplatser med cirka 50 undersidor och ett kontaktformulär som den svåraste konverteringen.
Eftersom sådana webbplatser troligen bara kräver data från frontend för att göra sin dataanalys, kan de klara sig med en enkel analysuppsättning utan något data layer. Det skulle inte göra insamlingsdelen mycket mer robust eller säkrare, varför dess fördelar minskar. Under sådana omständigheter rättfärdigar fördelarna inte den extra implementeringsinsatsen.
Typiska exempel när ett data layer inte är nödvändigt är broschyrwebbplatser eller innehållswebbplatser med ett begränsat antal eller nästan inga svåra konverteringar. Vanligtvis är sådana webbplatsägare bara intresserade av att kategorisera användarengagemanget efter deras innehållssektioner eller några företagsinterna klassificeringar.
Sådana krav kan uppnås med avancerad JavaScript och ett genomtänkt system för att strukturera innehållet.
Så snart datainsamlingen från frontend regelbundet bryter och definitivt när en databas bör vara inblandad, rekommenderas ett data layer.
Alternativa lösningar är ofta bara tillfälligt tillfredsställande, på grund av ständigt ökande analysambitioner och regelbundet brytande datainsamling. Dessutom är alla anpassade lösningar vanligtvis svåra att överlämna till en annan byrå.
Ett data layer har goda chanser att överleva tidens tand eftersom det redan är ett etablerat koncept inom webbanalyssektorn, så webbyråer har ökad erfarenhet av att implementera och underhålla ett.
Slutsats
Ett data-lager är guldstandarden för professionella analysuppsättningar. Det ökar datakvaliteten och förbättrar därmed dataanalysen som helhet, samtidigt som säkerhetskraven uppfylls.
För ambitiösa webbplatsägare som vill börja med seriös dataanalys är det den enklaste och mest robusta lösningen.
Om du har valet, implementera en array-baserad struktur, eftersom du har färre beroenden och kan använda den på alla typer av webbplatser.
Innehållswebbplatser är dock så begränsade i funktionalitet och ger vanligtvis bara ett begränsat antal svåra konverteringar, så ett data-lager kan potentiellt försummas. Detta gäller särskilt om all nödvändig data finns tillgänglig på sidorna eller kan göras tillgänglig genom några omvägar.
Om du vill implementera en själv är det förmodligen enklast att göra det med en WordPress-webbplats. Alla avancerade krav är dock förmodligen inte värda att spendera tiden på och riskera ett otillfredsställande resultat.
Därför är det vanligtvis bäst att implementera med hjälp av en analytisk konsult, eftersom det sparar tid och undviker onödiga risker.
Jag rekommenderar att du installerar en av de nämnda Chrome-tilläggen för att inspektera data-lager på några större webbplatser där ute. Det är vanligtvis en bra inspiration och ger några intressanta KPI:er att potentiellt integrera i dina egna analysuppsättningar 😉.
Dokumentation av Data Layer från olika TMS-leverantörer
- Google Tag Manager: Initiering och ändring av data
- Adobe Launch: Initiering
- Tealium iQ: Initiering och ändring av data
- Matomo: Initiering och ändring av data
- Piwik Pro: Initiering och ändring av data
FAQ
Vad är ett exempel på ett data-lager?
Ett exempel på ett data-lager finns i artikeln. Ett JavaScript-objekt lagrar data från en webbplats, databas eller en extern källa på ett centralt, flexibelt och lättillgängligt sätt. Ett exempel på kodsnutt för att initiera ett data-lager för Google Tag Manager är: window.dataLayer = window.dataLayer || [{ "pageCategory": "category page", "pageName": "sneaker overview", "language": "en-US",}];
Vad är data-lagervariabler?
Data-lagervariabler är nyckel-värde-par inom data-lagret som lagrar specifika informationsbitar. Dessa variabler kan inkludera sidkarakteristika, användarbeteendedata och mer, och fungerar som ett centralt datalager för analys och spårning.
Varför använda ett data-lager?
Ett data-lager är viktigt för robust, flexibel och säker datainsamling. Det centraliserar data från olika källor, vilket gör det lättillgängligt och konsekvent över olika webbsidor och användarinteraktioner. Detta tillvägagångssätt förbättrar datakvaliteten och tillförlitligheten, vilket är avgörande för datadrivna beslut.
Behöver jag ett data-lager?
Även om det inte alltid är nödvändigt, rekommenderas generellt ett data-lager för de som är seriösa med sina dataanalysambitioner. Det ger datakvalitet, tillförlitlighet och långsiktiga tidsbesparingar som motiverar de högre implementeringsinsatserna.
Vilka är fördelarna med ett data-lager?
Fördelarna med ett data-lager inkluderar: Tillgänglighet av data oavsett om den är synlig på sidan. Robust datainsamling. Förhindrande av dataförlust vid asynkrona databehov. Säker datainsamling från flera källor.
Har alla webbplatser ett data-lager?
Inte alla webbplatser har ett data-lager. Implementeringen beror på webbplatsens komplexitet och djupet av den dataanalys som krävs. Enkla webbplatser kanske inte har ett data-lager, medan mer komplexa webbplatser, särskilt de som fokuserar på datadrivna beslut, troligtvis kommer att ha ett.
Hur kommer jag åt data-lagret?
Data-lagret är globalt tillgängligt i webbläsarkonsolen. För webbplatser med Google Tag Manager kan du komma åt det med hjälp av dataLayer eller Object.assign(...dataLayer). För Adobe Launch eller DTM kan du komma åt det med hjälp av digitalData.
Hur pushar du till data-lagret?
För att pusha till data-lagret använder du metoden dataLayer.push(). Till exempel: window.dataLayer.push({ "event": "course-booking", "startWeek": "24" }); Denna metod används för att lägga till ny data eller ändringar till data-lagret. Event-nyckeln kan användas för att utlösa en annan taggexekvering i tagghanteringssystemet.
Ytterligare Resurser
- Simo Ahava om data-lagret i GTM och hur man hanterar data i det.
- Läs min Google Tag Manager-tutorial och lär dig hur man sätter upp det.
- Kevin Haags presentation från Measurecamp Berlin 2019 om Event Driven Data Layer i Adobe Analytics