Data Laag
In verband met tag management en web analytics, heb je misschien de term data laag gehoord. Het is het fundamentele element in een ambitieuze web analytics setup omdat alle datapunten en trackingregels ervan afhangen.
Daarom wordt het in de digitale analytics wereld behandeld als een niet-onderhandelbare vereiste voor elke analytics setup. Echter, er bestaan ook scenario's waarin het niet nodig is.
Daarom wil ik uitleggen wat een data laag is, de voordelen, en de verschillen tussen de data laag voor Google Tag Manager en Adobe Launch.
Daarna gaan we kijken naar de implementatie voor de meest populaire Tag Management Systemen (TMS). Ik zal de ontwerp fase uitleggen, gevolgd door de implementatie en debugging.
Wat is een data laag?
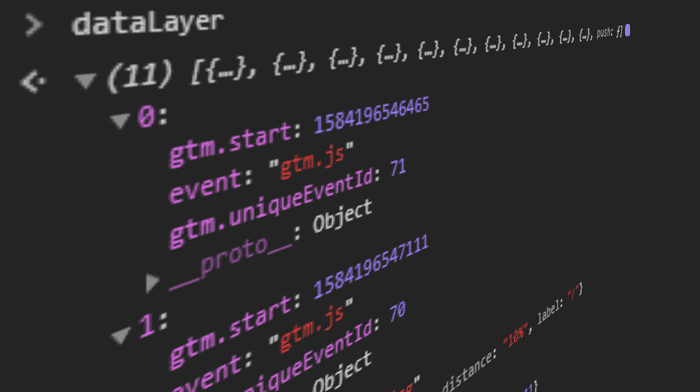
Een Data Laag is een datastructuur die relevante informatie in Key-Value Pairs biedt voor gebruik met bijvoorbeeld Tag Management Systemen.
Een Data Laag is beschikbaar in de globale JavaScript Scope van de website als een Array of Object en bevat data in een gestructureerde vorm voor gebruik door andere programma's.
Het voordeel van een Data Laag ligt in een programmatisch eenvoudige toegang tot relevante data tijdens een websitebezoek.
Het maakt toegang tot data mogelijk op één centraal punt en is de basis voor de data analytics logica in een tag management systeem.
window.dataLayer = window.dataLayer || [{"pageCategory": "categoriepagina","pageName": "sneakeroverzicht","language": "nl-NL",}];
Omdat het wordt gebruikt om data van meerdere databronnen op te slaan, vereenvoudigt het het monitoren van huidige datapunten, omdat slechts één enkele plaats moet worden geobserveerd ("single point of truth").
Een data laag wordt opnieuw opgebouwd bij elke paginalading en uitgerust met datapunten van de huidige webpagina en mogelijk andere gerelateerde data over de bezoeker en zijn bezoek.
Let op: Single page applications (SPA) laden de pagina niet opnieuw tussen de paginanavigatie door. Daarom is de configuratie van de data laag voor een single page application anders dan voor typische webpagina's met paginaladingen.
De opgeslagen data vertegenwoordigt kenmerken of eigenschappen van een subpagina en wordt opgeslagen in een key-value-pair. De sleutels bevatten beschrijvende namen van de eigenschappen, gekoppeld aan een huidige waarde, die doorgaans verandert tijdens de gebruikersreis.
window.dataLayer = window.dataLayer || [{"pageCategory": "categoriepagina", //categorie"pageName": "sneakeroverzicht", //naam"language": "nl-NL", //taal}];
Het algemene doel is om die datapunten beschikbaar te maken in het tag management systeem, zodat ze kunnen worden verzonden samen met de data die wordt gedeeld met bijvoorbeeld Google Analytics of Facebook Ads om website-interacties beter te beschrijven.
Om deze integratie mogelijk te maken, houdt het TMS verwijzingen naar de key-value-pairs en kan bijvoorbeeld regels uitvoeren zodra hun waarde verandert.
Voorbeeld: Een bezoeker zoomt in op een productafbeelding en triggert daarmee een event "product zoom". Zonder aanvullende data die samen met het event wordt verzonden, is het niet erg inzichtelijk. Daarom sturen we ook data over bijvoorbeeld de productnaam, categorie en prijs, zodat we het event in een betekenisvolle context kunnen analyseren.
De aanvullende data zou het mogelijk maken om te verifiëren of dergelijke productzooms alleen voorkomen in bepaalde productcategorieën. Als dat zo is, kan het nuttig zijn om meer afbeeldingen toe te voegen aan andere producten in dezelfde categorie, omdat bezoekers blijkbaar erg geïnteresseerd zijn in de afbeeldingsdetails van die producten.
Het komt erop neer dat we alle relevante data structureren in beschrijvende sleutels en waarden en deze beschikbaar maken op een centrale plek waar ze gemakkelijk kunnen worden opgepikt.
Dergelijke datapunten zijn meestal belangrijke kenmerken van de pagina-inhoud of een classificatie die we hebben bedacht om bezoekers te segmenteren op basis van gedrag.
Om beter te begrijpen wat een data laag is, kun je je als een vereenvoudigde visualisatie een Excel-sheet voorstellen. De sheet bevat belangrijke kenmerken van een webpagina in de kop (pad, taal, categorie, ingelogde status) samen met een huidige waarde voor elk item.

Wat zijn de voordelen van het gebruik van een data laag?
Terwijl een bezoeker door een website navigeert, vinden er veel gebruikersinteracties plaats: klikken op knoppen, ingevulde formulieren of bekeken video's.
Als die interacties ons in staat stellen conclusies te trekken over de gebruikersbetrokkenheid, worden ze verzonden naar bijvoorbeeld Google Analytics samen met andere beschrijvende data over de bezoeker, sessie, het event zelf of het HTML-element waarmee ze interacteerden.
En dit is het cruciale punt: De aanvullende data om dergelijke interacties te beschrijven komt uit verschillende databronnen, bijvoorbeeld van de frontend, database of een externe API.
Om de voordelen van een data laag te begrijpen, moeten we eerst de uitdagingen begrijpen die ontstaan wanneer we data van meerdere databronnen nodig hebben.
Laten we kijken naar een voorbeeld waarbij we data verzamelen van dergelijke bronnen en laten we het doordenken:
Voorbeeld: De bezoeker koopt een product op een website. De volgende dimensies kunnen van belang zijn:
- productnaam
- productprijs
- productmaat
- productcategorie
- productkleur
- winkelmandwaarde
- merk
- eerste aankoop
- klantsegment
- klantkorting
- geslacht
- land
Na de aankoop landen bezoekers op een bedankpagina met alle details van de aankoop en het bezorgadres.
Frontend: Om de productdata, winkelmandwaarde en merk samen met het event te verzenden, kunnen we het eventueel van de bedankpagina scrapen.
De grootste uitdaging van het scrapen van data van een webpagina is dat de data beschikbaar moet zijn op elke pagina waar de interactie plaatsvindt. Dit is in de praktijk zelden het geval.
Het is raadzaam om zoveel mogelijk dezelfde dimensies te meten bij alle interacties op een website, zodat de interacties later tijdens data-analyse vergelijkbaar zijn. Dus, als we die benadering zouden volgen, is het waarschijnlijk dat andere pagina's geen productdata, winkelmandwaarde en merknaam vermelden om mee te sturen met andere events.
Dus als de benodigde data niet beschikbaar is op andere pagina's, willen we vermijden dat we al die data aan de content toevoegen enkel en alleen voor analytics. Daarom gebruiken we een data laag. Het maakt de data voor ons beschikbaar om te verzamelen, ongeacht of het zichtbaar is op de pagina of niet. Het is letterlijk een laag van data die bovenop elke subpagina zit en de data levert die we nodig hebben.
Een andere uitdaging van het scrapen van data van de frontend is dat het uiteindelijk breekt. Wanneer pagina's worden gewijzigd en die wijzigingen de HTML-structuur van de gescrapete elementen beïnvloeden, dan zal de dataverzameling breken. Vooral in grotere bedrijven zijn er frequente wijzigingen op pagina's en werken er meerdere teams aan zonder te weten of sommige HTML-elementen nodig zijn voor dataverzameling. Daarom zal elke scraping van data van de frontend op een gegeven moment breken op vaak bijgewerkte websites.
Een data laag benut deze aanpak en maakt het mogelijk om gebruikersdata op een veilige en toch eenvoudige manier op te halen.
Database: Het verzamelen van klantdata (klantsegment, korting, geslacht en eerste aankoop) kan ingewikkeld worden: Klantdata zou ofwel met de serverrespons moeten worden meegestuurd of met een aparte API.
Maar aangezien dit privégegevens zijn, moet de verzameling worden geauthenticeerd voor gegevensbeschermingsdoeleinden. Dat betekent dat een API-verzoek niet in de browser kan worden afgehandeld omdat de API-sleutel anders door ervaren gebruikers zou kunnen worden opgehaald.
Daarom is de beste oplossing om de data samen met de serverrespons te verzenden op basis van de inlogauthenticatie van de website.
Wanneer de gebruiker is ingelogd, wordt de data laag gevuld met de relevante data uit de database. Zonder inloggen worden er geen gevoelige gegevens blootgesteld.
API: Geo data zoals het land kan worden opgehaald via een externe service API.
Echter, dezelfde uitdaging als bij het ophalen van data uit de database doet zich voor: Elke API-aanvraag van de frontend of het tag management systeem vereist een API-sleutel, die om veiligheidsredenen niet in de browser moet worden behandeld.
Een ander nadeel van werken met API's voor dataverzameling, vooral bij events, is de duur totdat de data terugkomt. Als een gebruiker naar een andere pagina navigeert voordat de data is aangekomen, riskeren we het event te verliezen.
Laten we de voordelen snel samenvatten:
Voordelen
- Data is beschikbaar, ongeacht of het zichtbaar is op de pagina
- Robuuste dataverzameling
- Veilige verzameling van gevoelige data
- Verminderen van dataverlies bij asynchrone data-aanvragen
Waarom je waarschijnlijk een data laag nodig hebt
Door een data laag te creëren, wordt een JavaScript-object beschikbaar gemaakt in de globale scope van de browser bij elke paginalading.
De data die het bevat kan afkomstig zijn van je database, frontend of API's, zodat dataverzameling van die bronnen betrouwbaar, veilig en onafhankelijk van de HTML op de pagina wordt.
Data uit de database kan zonder veel moeite beschikbaar worden gemaakt op elke subpagina van de site zonder zichtbaar te zijn in de content.
Om bovenstaande redenen adviseer ik klanten over het algemeen om data lagen te implementeren als ze serieus zijn over hun data-analyse ambities. De voordelen van datakwaliteit, betrouwbaarheid en de bijbehorende tijdsbesparing op de lange termijn rechtvaardigen de hogere implementatie-inspanningen.
Het uiteindelijke doel van webanalytics is om datagestuurde zakelijke beslissingen te nemen, dus datakwaliteit moet een prioriteit zijn.
Laten we nu kijken naar de verschillende beschikbare opties en enkele implementatievoorbeelden voordat we de ontwerp- en implementatiefase induiken.
Data Laag voor Adobe Analytics, DTM, Launch en Tealium
Data lagen kunnen verschillende structuren hebben. Over het algemeen maken we onderscheid tussen degenen met een objectgebaseerde structuur en een arraygebaseerde structuur.
Volgens de data laag definitie van het World Wide Web Consortium (W3C) volgt de syntaxis die van een JavaScript-object. Het wordt onofficieel afgekort als CEDDL (Customer Experience Digital Data Layer).
Je kunt er ook andere objecten of arrays in nesten:
window.digitalData = {pageName: "sneakeroverzicht",destinationPath: "/nl/sneakers",breadCrumbs: ["home","sneakers"],publishDate: "2020-07-01",language: "nl-NL"};
Adobe Analytics, Adobe Launch en Tealium volgen de CEDDL-structuur. In het bovenstaande voorbeeld slaan we data op in een object genaamd digitalData. De naam is niet gestandaardiseerd en kan vrij worden gekozen, maar je moet de naam wel declareren in het tag management systeem.
Om de data te wijzigen, zijn er meerdere opties (zoals bij elk JS-object), maar de eenvoudigste manier is om gewoon de waarden te overschrijven:
window.digitalData.language = "de-DE";
Het centrale idee van de objectgebaseerde structuur is dat ze eenmaal per paginalading worden geladen, maar ze worden niet veel gewijzigd op basis van gebruikersinteractie. De data is meestal statisch.
Event tracking wordt niet gedreven door events die het data laag object binnenkomen. Events worden getrackt met een aparte trackingbibliotheek om ze verder te sturen naar een analytics platform, bijvoorbeeld Adobe Analytics. Wanneer de event tracking code wordt uitgevoerd, wordt het data laag object in zijn geheel meegestuurd en kan worden gebruikt tijdens data-analyse.
//Event met gekozen kleur_satellite.setVar("sneaker kleur", "zwart");_satellite.track("selecteer kleur");
Gebruik Adobe Launch met een array-gebaseerde data laag
Je kunt Adobe Launch ook gemakkelijk gebruiken met een array-gebaseerde structuur. De Adobe Launch Extension Data Layer Manager maakt dit mogelijk.
Hier zijn enkele links naar verdere bronnen voor het gebruik van de array-gebaseerde versie met Adobe Launch:
- Jim Gordon’s Demo van het gebruik van Data Layer Manager met Adobe Launch
- Data Layer Manager Extensie met documentatie
Data Laag voor Google Tag Manager, Matomo en Piwik Pro
De data laag voor Google Tag Manager, Matomo en Piwik Pro is array-gebaseerd en wordt onofficieel aangeduid als de event-driven data layer (EDDL).
Data wordt ook in objecten verwerkt, maar de algemene structuur van de GTM data laag is een array met objecten.
window.dataLayer = window.dataLayer || [{"pageCategory": "categoriepagina","pageName": "sneakeroverzicht","language": "nl-NL",}];
De tracking-logica met een array-gebaseerde structuur is anders: Nieuwe data of wijzigingen worden erin gepusht via dataLayer.push(). Een push naar de data laag kan vervolgens tag-uitvoeringen in het tag management systeem triggeren.
Het fundamentele verschil met een objectgebaseerde structuur is dat wijzigingen meestal samen met een event worden verzonden en dat regels worden getriggerd op basis van die wijzigingen zonder enige extra bibliotheek, alleen door te observeren of de data laag array verandert.
Aangezien er geen andere bibliotheek zoals _satellite nodig is, hebben we één afhankelijkheid minder.
Een ander kenmerk van de array-gebaseerde benadering is dat de data vrij vaak verandert gedurende de gebruikersreis, omdat elke gebruikersinteractie de data laag variabelen kan wijzigen.
Dus een array-gebaseerde data laag is de basis voor event tracking en verwerkt data flexibeler, terwijl een objectgebaseerde eerder dient als een statische datastorage.
Door die flexibiliteit wordt gezegd dat een array-gebaseerde data laag structuur geschikter is voor Single-Page-Applications.
Je kunt echter ook SPAs tracken met een objectgebaseerde data laag, het vereist alleen een paar extra regels code en mogelijk enkele edge cases om op te lossen.
Als je aan het begin van een project staat en de keuze hebt, geef ik de voorkeur aan een array-gebaseerde data laag.
Het veranderen van een al bestaande setup van een objectstructuur naar een array is echter onnodig.
Content Management Systemen met ingebouwde data laag
WordPress-gebruikers hebben het gemakkelijk omdat ze deze plugin kunnen gebruiken om Google Tag Manager te implementeren samen met een vooraf geconfigureerde data laag.
Het vult automatisch categorieën, auteursnamen, publicatiedata en zoektermen in.
De datapunten kunnen worden aangevinkt of uitgevinkt in de plugin-instellingen. Verder biedt de plugin vooraf geconfigureerde events voor formulierinzendingen van de meest voorkomende formplugins.
Als je een webshop eigenaar bent en WooCommerce voor WordPress gebruikt, kun je een klassieke e-commerce data laag evenals een verbeterde e-commerce data laag implementeren met dezelfde plugin, wat behoorlijk krachtig is.
WordPress-gebruikers die Tealium willen gebruiken, kunnen een plugin voor Tealiumgebruiken.
Drupal heeft ook een plugin.
Wix en Squarespace-gebruikers kunnen Google Tag Manager implementeren via de platformtools maar moeten de data laag code handmatig implementeren.
Implementatie van de data laag
Dus hoe implementeer je een data laag? - Aangezien planning en implementatie kennis vereisen op het gebied van digitale analytics, frontend ontwikkeling en backend ontwikkeling, wordt de implementatie meestal uitgevoerd door een webbureau samen met een analytics consultant.
De analytics consultant informeert het webbureau en leidt het project totdat de implementatie succesvol is gevalideerd. Vervolgens worden het tag management systeem en de analytics tools geconfigureerd.
Als je geïnteresseerd bent en wat JavaScript-kennis hebt, kun je het zelf implementeren met de volgendeimplementatiegids.
De implementatie doorloopt 3 stappen:
1. Data Laag Ontwerp
De ontwerpfase draait om het definiëren van welke interacties moeten worden gemeten samen met welke dimensies.
Alle attributen van de bezoeker, sessie, pagina, product of gebeurtenis kunnen van potentieel belang zijn tijdens data-analyse en moeten worden overwogen voor de data laag architectuur.
Om te beslissen wat moet worden opgenomen, begin je met het eind in gedachten en vraag je jezelf af welke bedrijfskritische vragen moeten worden beantwoord en beperk je tot de gerelateerde datapunten.
De volgende stap is om uit te zoeken hoe die datapunten moeten worden gestructureerd en welke dimensies het belangrijkst zijn om toe te voegen.
Voorbeeld: Een talenschool die een WordPress-website in meerdere talen beheert, wil de moedertaal van hun websitebezoekers weten en welke vreemde taal ze het meest interesseren. Het doel is om mogelijk online advertenties te plaatsen via Facebook Ads gericht op demografieën met vergelijkbare attributen.
Als volgende stap moeten we alle relevante data definiëren voor verschillende soorten pagina's (homepage, cursuspagina's, over ons, contact en nieuws). Om te vereenvoudigen, kijken we naar de meest interessante pagina's en richten we ons op de homepage en cursuspagina's.

Voorbeeld: Array-gebaseerde Google Tag Manager data laag voor een talenschool
window.dataLayer = window.dataLayer || [{"language": "nl", //Taal van de UI"sessionDuration": "182", //Sessie duur in seconden"languageIntent": "es", //meest bezochte cursus taal"pageType": "cursuspagina","courseName": "Spaans A1 - Beginner","courseLang": "es","courseLevel": "a1","courseDuration": "6" //Duur in weken}];
Voorbeeld: Object-gebaseerde data laag voor Adobe Launch
window.digitalData = window.digitalData || {"language": "nl", //Taal van de UI"sessionDuration": 182, //Sessieduur in seconden"languageIntent": "es", //Meest bezochte cursus taal"pageType": "cursuspagina","courseName": "Spaans A1 - Beginner","courseLang": "es","courseLevel": "a1","courseDuration": 6 //Duur in weken};
2. Implementatie
Data lagen moeten op elke subpagina van een website worden geïmplementeerd. De bovenstaande codevoorbeelden tonen echter de uiteindelijke berekende staat.
Tijdens de implementatie moeten de datapunten eerst worden verzameld om te worden berekend naar hun uiteindelijke staat, dus de daadwerkelijke bron ziet er iets anders uit.
Om een realistisch voorbeeld te geven, ga ik echter uit van het volgende:
- Sessieduur en taalinteresse worden verzameld via een zelfgemaakte JavaScript en opgeslagen in de lokale opslag van de browser.
- Taal, paginatype en cursusgegevens kunnen worden opgehaald uit de database via de serverrespons en beschikbaar worden gesteld op de cursussjablonen en de homepage.
De broncode van de data laag in de backend volgens bovenstaande veronderstellingen zou er zo uitzien:
window.dataLayer = window.dataLayer || [{"language": <?php echo wpb_getpagedata("lang"); ?>,"sessionDuration": window.localStorage.sessionDuration,"languageIntent": window.localStorage.languageIntent"pageType": <?php echo wpb_getpagedata("type"); ?>,"courseName": <?php echo wpb_getcoursedata("name"); ?>,"courseSprache": <?php echo wpb_getcoursedata("lang"); ?>,"courseLevel": <?php echo wpb_getcoursedata("level"); ?>,"courseDuration": <?php echo wpb_getcoursedata("duration"); ?>,}];
Event tracking met data laag push
Om events naar een GTM data laag te sturen, kun je de push-methode gebruiken en letterlijk events erin pushen.
window.dataLayer.push({"event": "cursus-boeking","startWeek": "24"});
Het event sleutelwoord is een speciaal sleutelwoord en kan worden aangesproken als een custom event vanuit de GTM-container.
Het tag management systeem observeert de data laag en voert een tag uit zodra een vooraf gedefinieerde custom event naar het systeem wordt verzonden.
Nadat een event is toegevoegd, kan het TMS bijvoorbeeld een event naar Google Analytics sturen.
Alle relevante data om context te bieden (naam, taal, taalniveau, cursusduur) is beschikbaar en kan samen met het event worden verzonden, bijvoorbeeld de startweek voor de cursus.
In een object-gebaseerde data laag zou hetzelfde event direct naar Adobe Analytics worden gestuurd via hun eigen event trackingbibliotheek.
Voor Adobe Launch zou de voorbeeldcode er zo uitzien:
_satellite.setVar("startWeek", 24);_satellite.track("cursus-boeking");
Code positionering in de broncode
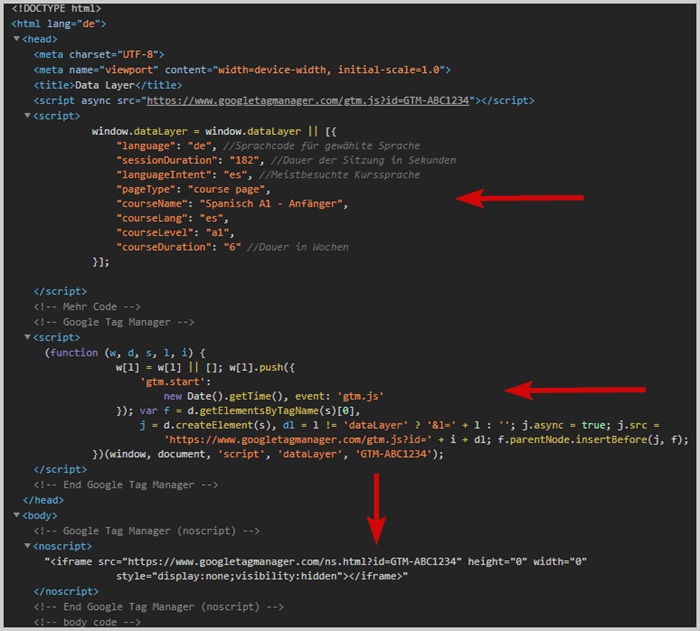
De data laag code moet worden toegevoegd in de <head> van de pagina vóór het tag management systeem.
Door deze volgorde zorg je ervoor dat het al is berekend wanneer het tag management systeem er toegang toe wil hebben.
Voorbeeld: Positionering in de broncode
3. Debugging
De meest voorkomende procedures om een data laag te debuggen zijn het simuleren van paginaladingen of events om te verifiëren dat alle datapunten worden gevuld met de juiste data.
Omdat het globaal toegankelijk is in de browserconsole, kun je eenvoudig alle waarden naar de console printen (ervan uitgaande dat standaard naamgevingsconventies worden toegepast):
Websites met GTM
Object.assign(...dataLayer)
Websites met Adobe Launch of DTM
digitalData
Tealium
utag.data of utag_data
Google Tag Manager heeft zelfs een eigen Debugger Mode. Je kunt deze activeren vanuit de GTM interface door rechtsboven op preview te klikken.
Als je geen toegang hebt tot de tag management container maar deze toch wilt debuggen, kun je een chrome-extensie gebruiken.
Data Laag Chrome-extensies
Er is een verscheidenheid aan mogelijke extensies voor debugging beschikbaar. Ik geef de voorkeur aan degene die de meeste leveranciers ondersteunen, zodat ik niet tussen extensies hoef te wisselen bij het debuggen van een andere site.
De volgende Chrome-extensies zijn momenteel mijn favorieten voor debugging:
- Trackie - Extensie gebaseerd op Data Slayer en open source. Het heeft een goede prestatie en ondersteunt GTM, DTM, Tealium en nog veel meer.
- Omnibug - Nog een alleskunner met ondersteuning voor Adobe Analytics (DTM & Launch), evenals Matomo, GTM, Tealium en meer.
Chrome-extensies voor het debuggen van Google Analytics en GTM
- GTM/GA Debug - na het activeren van de extensie zal er een nieuw tabblad beschikbaar zijn in Chrome DevTools zodra je deze opent (F12 op Windows en CTRL+SHIFT+i op Mac). Alle relevante data wordt weergegeven in een grafische UI en wordt bijgewerkt terwijl je een website bekijkt.
- Adswerve - dataLayer Inspector+ - logt alle relevante datapunten in de browserconsole. Activeer "preserve log" in de console-instellingen om logs te behouden tijdens paginanavigatie.
- Data Slayer - zeker de extensie met de coolste naam en logo en mijn vorige favoriet. Het is open source met een eenvoudige layout en werkt ook met Adobe DTM.
Vink “gebruik drie-koloms layout waar beschikbaar”, “toon GA Classic tags” en “toon Floodlight tags” uit in de extensie-instellingen, anders worden de logs een beetje rommelig.
Chrome-extensies voor het debuggen van Adobe Analytics, Launch en DTM
- Launch & DTM Switch - stelt je in staat om de staging- of productiebibliotheek van het tag management systeem te laden en kan de debugmodus activeren.
- Debugger voor Adobe Analytics - activeert de debugmodus. Als alternatief kun je ook
_satellite.setDebug(true)in de console typen. - Adobe Experience Cloud Debugger - meta-extensie om alle Adobe-producten te debuggen.
- Adobe Experience Platform Debugger - opvolger van de experience cloud debugger die een beter overzicht biedt (momenteel nog in bèta).
- Tealium Data Layer Debugger - eenvoudige tabellen van alle huidige waarden.
E-commerce Data Laag
Data lagen voor e-commerce zijn uitgebreider en hun structuur is complexer. Ze moeten meer data bevatten en meer events beheren.
Daarom neemt de planning en implementatie van een e-commerce website aanzienlijk meer tijd in beslag.
Het e-commerce rapport in Google Analytics, bijvoorbeeld, toont geen gegevens als de implementatie hun e-commerce data laag documentatie niet volgt.
Grote e-commerce winkels vereisen echter nog geavanceerdere trackingopstellingen. Ze implementeren een data laag voor geavanceerde e-commerce, wat nog meer functionaliteit in Google Analytics mogelijk maakt.
Je moet de implementatierichtlijnen voor Google Analytics strikt volgen om de e-commerce rapporten te laten werken. Dat betreft de structuur van de data laag en ook de variabelenamen.
Als je een ander analytics platform kiest voor e-commerce, ben je vrij om de structuur naar eigen inzicht te plannen.
Wanneer is een data laag niet nodig?
Zoals met alles, zijn er ook gevallen waarin de extra inspanning van het implementeren van een data laag niet gerechtvaardigd is.
In de bovenstaande voorbeelden hebben we gekeken naar gevallen waarin we data uit verschillende databronnen haalden (Frontend, Backend, API) en problemen oplosten die zich voordeden bij het werken met een verscheidenheid aan databronnen.
Veel websites (zogenaamde brochure-websites) hebben echter niet eens een inlogfunctionaliteit en hebben ook geen database.
Een andere belangrijke factor is hoe vaak er wijzigingen op de website worden doorgevoerd. Veel sites beoordelen zelden hun inhoud of voegen regelmatig functionaliteit toe. Ik zie zelfs ondernemingen eenvoudige brochure-websites draaien met ongeveer 50 subpagina's en een contactformulier als de belangrijkste conversie.
Aangezien dergelijke sites waarschijnlijk alleen data van de frontend nodig hebben om hun data-analyse uit te voeren, kunnen ze volstaan met een eenvoudige analytics opstelling zonder data laag. Het zou de verzameling niet veel robuuster of veiliger maken, dus de voordelen worden gemitigeerd. Onder dergelijke omstandigheden rechtvaardigen de voordelen niet de extra inspanning van implementatie.
Typische voorbeelden waarbij een data laag niet nodig is, zijn brochuresites of inhoudwebsites met een beperkt aantal of bijna geen harde conversies. Meestal zijn de eigenaren van dergelijke sites gewoon geïnteresseerd in het categoriseren van de gebruikersbetrokkenheid op basis van hun inhoudssecties of enkele bedrijfsinterne classificaties.
Dergelijke vereisten kunnen worden bereikt met geavanceerde JavaScript en een goed doordacht systeem voor het structureren van de inhoud.
Zodra de dataverzameling van de frontend regelmatig breekt en zeker wanneer er een database moet worden betrokken, wordt een data laag aanbevolen.
Alternatieve oplossingen zijn vaak slechts tijdelijk bevredigend, vanwege steeds groeiende analytics ambities en regelmatig brekende dataverzameling. Ook zijn aangepaste oplossingen meestal moeilijk door te geven aan een ander bureau.
Een data laag heeft goede kansen om de tand des tijds te doorstaan, omdat het al een gevestigd concept is in de web analytics sector, dus webbureaus hebben toenemende ervaring met het implementeren en onderhouden ervan.
Conclusie
Een datalaag is de gouden standaard voor professionele analytische opstellingen. Het verhoogt de datakwaliteit en verbetert daardoor de gegevensanalyse als geheel, terwijl het voldoet aan de beveiligingseisen.
Voor ambitieuze website-eigenaren die willen beginnen met serieuze gegevensanalyse, is het de gemakkelijkste en meest robuuste oplossing.
Als je de keuze hebt, implementeer dan een op array gebaseerde structuur, aangezien je minder afhankelijkheden hebt en het op alle soorten websites kunt gebruiken.
Contentwebsites hebben echter zo weinig functionaliteit en brengen meestal slechts een beperkte hoeveelheid harde conversies met zich mee, waardoor een datalaag mogelijk kan worden verwaarloosd. Dit geldt vooral als alle benodigde gegevens beschikbaar zijn op de pagina's of beschikbaar kunnen worden gemaakt via enkele omwegen.
Als je er zelf een wilt implementeren, is het waarschijnlijk het gemakkelijkst om dit met een WordPress-website te doen. Alle geavanceerde vereisten zijn echter waarschijnlijk niet de tijd en het risico van een onbevredigend resultaat waard.
Daarom is implementeren met de hulp van een analytics-consultant meestal de juiste weg, omdat het tijd bespaart en onnodige risico's vermijdt.
Ik raad je aan om een van de genoemde Chrome-extensies te installeren om de datalagen van enkele grotere websites te inspecteren. Dit is meestal een geweldige inspiratiebron en levert enkele interessante KPI's op om mogelijk te integreren in je eigen analytische opstellingen 😉.
Datalaagdocumentatie van verschillende TMS-leveranciers
- Google Tag Manager: Initiëren en gegevens wijzigen
- Adobe Launch: Initiëren
- Tealium iQ: Initiëren en Gegevens wijzigen
- Matomo: Initiëren en gegevens wijzigen
- Piwik Pro: Initiëren en gegevens wijzigen
FAQ
Wat is een voorbeeld van een datalaag?
Een voorbeeld van een datalaag wordt in het artikel gegeven. Een JavaScript-object slaat gegevens van een website, database of een externe bron op in een centrale, flexibele en gemakkelijk toegankelijke manier. Een voorbeeld van een codefragment voor het initiëren van een datalaag voor Google Tag Manager is: window.dataLayer = window.dataLayer || [{ "pageCategory": "category page", "pageName": "sneaker overzicht", "language": "nl-NL",}];
Wat zijn datalaagvariabelen?
Datalaagvariabelen zijn sleutel-waardeparen binnen de datalaag die specifieke informatie opslaan. Deze variabelen kunnen paginakentmerken, gebruikersgedragsgegevens en meer bevatten, en dienen als een centrale gegevensrepository voor analytics en tracking.
Waarom een datalaag gebruiken?
Een datalaag is essentieel voor robuuste, flexibele en veilige gegevensverzameling. Het centraliseert gegevens van verschillende bronnen, waardoor ze gemakkelijk toegankelijk en consistent zijn over verschillende webpagina's en gebruikersinteracties. Deze aanpak verbetert de gegevenskwaliteit en betrouwbaarheid, wat cruciaal is voor datagestuurde besluitvorming.
Heb ik een datalaag nodig?
Hoewel het niet altijd noodzakelijk is, wordt een datalaag over het algemeen geadviseerd voor diegenen die serieus zijn over hun gegevensanalyse-ambities. Het biedt gegevenskwaliteit, betrouwbaarheid en tijdsbesparingen op de lange termijn die de hogere implementatie-inspanningen rechtvaardigen.
Wat zijn de voordelen van een datalaag?
De voordelen van een datalaag zijn onder andere: Beschikbaarheid van gegevens, ongeacht de zichtbaarheid ervan op de pagina. Robuuste gegevensverzameling. Vermindering van gegevensverlies bij asynchrone gegevensaanvragen. Veilige gegevensverzameling uit meerdere bronnen.
Hebben alle websites een datalaag?
Niet alle websites hebben een datalaag. De implementatie ervan hangt af van de complexiteit van de website en de diepgang van de vereiste gegevensanalyse. Eenvoudige websites hebben mogelijk geen datalaag, terwijl complexere sites, vooral die gericht zijn op datagestuurde besluitvorming, dit waarschijnlijk wel hebben.
Hoe krijg ik toegang tot de datalaag?
De datalaag is wereldwijd toegankelijk in de browserconsole. Voor websites met Google Tag Manager kun je er toegang toe krijgen met dataLayer of Object.assign(...dataLayer). Voor Adobe Launch of DTM kun je er toegang toe krijgen met digitalData.
Hoe voeg je gegevens toe aan de datalaag?
Om gegevens toe te voegen aan de datalaag, gebruik je de methode dataLayer.push(). Bijvoorbeeld: window.dataLayer.push({ "event": "course-booking", "startWeek": "24" }); Deze methode wordt gebruikt om nieuwe gegevens of wijzigingen toe te voegen aan de datalaag. De event-sleutel kan worden gebruikt om een andere tag-uitvoering in het tag-beheersysteem te activeren.
Wat zijn de voordelen van een datalaag?
De voordelen van een datalaag zijn onder andere: Beschikbaarheid van gegevens, ongeacht de zichtbaarheid ervan op de pagina. Robuuste gegevensverzameling. Vermindering van gegevensverlies bij asynchrone gegevensaanvragen. Veilige gegevensverzameling uit meerdere bronnen.
Verdere Bronnen
- Simo Ahava over de datalaag in GTM en hoe je gegevens hierin beheert.
- Lees mijn Google Tag Manager handleiding en leer hoe je het instelt.
- Kevin Haag’s presentatie van Measurecamp Berlin 2019 over de Event Driven Data Layer in Adobe Analytics