Couche de Données
En relation avec la gestion des balises et l'analyse web, vous avez peut-être entendu le terme couche de données. C'est l'élément fondamental dans une configuration d'analyse web ambitieuse car tous les points de données et règles de suivi en dépendent.
C'est pourquoi dans le domaine de l'analytique numérique, il est traité comme une exigence non négociable pour toute configuration d'analyse. Cependant, il existe également des scénarios où ce n'est pas nécessaire.
Par conséquent, je veux expliquer ce qu'est une couche de données, ses avantages, et les différences entre la couche de données pour Google Tag Manager et Adobe Launch.
Ensuite, nous examinerons l'implémentation pour les systèmes de gestion des balises (TMS) les plus populaires. Je vais expliquer la phase de conception, suivie par l'implémentation et le débogage.
Qu'est-ce qu'une couche de données ?
Une couche de données est une structure de données qui fournit des informations pertinentes sous forme de paires clé-valeur pour une utilisation avec, par exemple, les systèmes de gestion des balises.
Une couche de données est disponible dans la portée globale de JavaScript du site web sous forme de tableau ou objet et contient des données structurées pour être utilisées par d'autres programmes.
Le bénéfice d'une couche de données réside dans un accès programmatique simple aux données pertinentes pendant une visite sur le site web.
Elle permet l'accès aux données en un point central et constitue la base de la logique d'analyse des données dans un système de gestion des balises.
window.dataLayer = window.dataLayer || [{"pageCategory": "category page","pageName": "sneaker overview","language": "en-US",}];
Comme elle est utilisée pour stocker des données provenant de multiples sources, elle simplifie la surveillance des valeurs de données actuelles, car il suffit d'observer un seul endroit ("point de vérité unique").
Une couche de données est reconstruite à chaque chargement de page avec des points de données de la page web actuelle et éventuellement d'autres données pertinentes sur le visiteur et sa visite.
Remarque : Les applications à page unique (SPA) ne rechargent pas la page entre les navigations. C'est pourquoi la configuration de la couche de données pour une application à page unique est différente de celle des pages web typiques avec rechargement de page.
Les données détenues représentent des caractéristiques ou des fonctionnalités d'une sous-page et sont conservées sous forme de paires clé-valeur. Les clés contiennent des noms descriptifs des fonctionnalités associés à une valeur actuelle, qui change généralement au cours du parcours utilisateur.
window.dataLayer = window.dataLayer || [{"pageCategory": "category page", //category"pageName": "sneaker overview", //name"language": "en-US", //language}];
L'objectif global est de rendre ces points de données disponibles dans le système de gestion des balises, afin qu'ils puissent être envoyés avec les données partagées avec, par exemple, Google Analytics ou Facebook Ads pour mieux décrire les interactions sur le site web.
Pour permettre cette intégration, le TMS contient des références aux paires clé-valeur et peut, par exemple, exécuter des règles lorsque leur valeur change.
Exemple : Un visiteur zoome sur une image de produit et déclenche ainsi un événement "zoom produit". Sans données supplémentaires envoyées avec l'événement, ce n'est pas très instructif. C'est pourquoi nous envoyons également des données sur, par exemple, le nom du produit, sa catégorie et son prix, afin que nous puissions analyser l'événement dans un contexte significatif.
Les données supplémentaires permettraient de vérifier si ces zooms de produit ne se produisent que dans certaines catégories de produits. Si c'est le cas, il peut être avantageux d'ajouter plus d'images à d'autres produits de la même catégorie, car les visiteurs semblent très intéressés par les détails des images de ces produits.
En fin de compte, nous structurons toutes les données pertinentes en clés et valeurs descriptives et les rendons disponibles en un endroit central où elles peuvent être facilement récupérées.
Ces points de données sont généralement des caractéristiques importantes du contenu de la page ou une classification que nous avons établie pour segmenter les visiteurs en fonction de leur comportement.
Pour mieux comprendre ce qu'est une couche de données, comme visualisation simplifiée, vous pouvez imaginer une feuille Excel. La feuille contient des caractéristiques importantes sur une page web dans son en-tête (chemin, langue, catégorie, statut de connexion) avec une valeur actuelle pour chaque élément.

Quels sont les avantages d'utiliser une couche de données ?
Lorsqu'un visiteur navigue sur un site web, de nombreuses interactions utilisateur ont lieu : clics sur des boutons, formulaires remplis ou vidéos regardées.
Si ces interactions nous permettent de tirer des conclusions sur l'engagement des utilisateurs, elles sont envoyées par exemple à Google Analytics avec d'autres données descriptives sur le visiteur, la session, l'événement lui-même ou l'élément HTML avec lequel ils ont interagi.
Et c'est le point crucial : Les données supplémentaires pour décrire ces interactions proviennent de différentes sources de données, par exemple du frontend, de la base de données ou d'une API externe.
Pour comprendre les avantages d'une couche de données, nous devons d'abord comprendre les défis qui se posent lorsque nous avons besoin de données provenant de multiples sources.
Voyons un exemple où nous collectons des données de ces sources et réfléchissons-y :
Exemple : Le visiteur achète un produit sur un site web. Les dimensions suivantes pourraient être intéressantes :
- nom du produit
- prix du produit
- taille du produit
- catégorie de produit
- couleur du produit
- valeur du panier
- marque
- premier achat
- segment de clientèle
- remise client
- genre
- pays
Après l'achat, les visiteurs arrivent sur une page de remerciement listant tous les détails de l'achat et de l'adresse de livraison.
Frontend : Pour envoyer les données du produit, la valeur du panier et la marque avec l'événement, nous pouvons potentiellement les extraire de la page de remerciement.
Le principal défi de l'extraction de données d'une page web est que les données doivent être disponibles sur chaque page où l'interaction a lieu. Ce n'est guère le cas en réalité.
Il est conseillé de mesurer autant de dimensions similaires à travers toutes les interactions d'un site web pour rendre les interactions comparables lors de l'analyse des données. Ainsi, si nous suivons cette approche, il est probable que d'autres pages ne listent pas les données du produit, la valeur du panier et le nom de la marque à envoyer avec d'autres événements.
Donc, si les données nécessaires ne sont pas disponibles sur d'autres pages, nous voulons éviter d'ajouter toutes ces données au contenu juste pour l'analyse. C'est pourquoi nous utilisons une couche de données. Elle rend les données disponibles pour que nous puissions les collecter, qu'elles soient visibles sur la page ou non. C'est littéralement une couche de données qui repose sur n'importe quelle sous-page donnée, fournissant les données dont nous avons besoin.
Un autre défi de l'extraction de données du frontend est qu'elle finit par se briser. Lorsque les pages sont modifiées et que ces changements affectent la structure HTML des éléments extraits, alors la collecte de données échouera. Surtout dans les grandes entreprises, il y a des changements fréquents sur les pages et plusieurs équipes y travaillent sans savoir si certains éléments HTML sont nécessaires pour la collecte de données. Ainsi, toute extraction de données à partir du frontend se brisera à un moment donné sur des sites fréquemment mis à jour.
Une couche de données exploite cette approche et permet de récupérer les données utilisateur de manière sécurisée et pourtant simple.
Base de données : Collecter les données client (segment de clientèle, remise, genre et premier achat) peut devenir compliqué : Les données client doivent soit être envoyées avec la réponse du serveur, soit avec une API distincte.
Mais comme il s'agit de données privées, la collecte doit être authentifiée pour des raisons de protection des données. Cela signifie qu'une requête API ne pourrait pas être gérée dans le navigateur car la clé API serait autrement récupérable par des utilisateurs expérimentés.
Par conséquent, la meilleure solution est d'envoyer les données avec la réponse du serveur en fonction de l'authentification de connexion du site web.
Lorsque l'utilisateur est connecté, la couche de données est remplie avec les données pertinentes de la base de données. Sans connexion, aucune donnée sensible n'est exposée.
API : Les données géographiques telles que le pays peuvent être récupérées à partir d'une API de service externe.
Cependant, le même défi se pose lors de la récupération de données à partir de la base de données : Toute requête API depuis le frontend ou le système de gestion des balises nécessite une clé API, qui ne devrait pas être gérée dans le navigateur pour des raisons de sécurité.
Un autre inconvénient du travail avec des API pour la collecte de données, en particulier avec des événements, est la durée jusqu'à ce que les données reviennent. Si un utilisateur navigue vers une autre page avant que les données n'arrivent, nous risquons de perdre l'événement.
Résumons rapidement les avantages :
Avantages
- Les données sont disponibles, qu'elles soient visibles sur la page ou non
- Collecte de données robuste
- Collecte sécurisée de données sensibles
- Réduction de la perte de données pour les requêtes de données asynchrones
Pourquoi vous en avez probablement besoin
En créant une couche de données, un objet JavaScript est rendu disponible dans la portée globale du navigateur à chaque chargement de page.
Les données qu'il contient peuvent provenir de votre base de données, du frontend ou des API, de sorte que la collecte de données à partir de ces sources devient fiable, sécurisée et indépendante du HTML sur la page.
Les données de la base de données peuvent être rendues disponibles sur n'importe quelle sous-page du site sans beaucoup de tracas sans être visibles dans le contenu.
Pour les raisons ci-dessus, je conseille généralement aux clients de mettre en œuvre des couches de données s'ils prennent leurs ambitions d'analyse de données au sérieux. Les avantages en termes de qualité des données, de fiabilité et de gain de temps à long terme justifient les efforts d'implémentation plus élevés.
L'objectif ultime de l'analyse web est de prendre des décisions commerciales basées sur les données, donc la qualité des données doit être une priorité.
Maintenant, regardons les différentes options disponibles et quelques exemples d'implémentation avant de plonger dans la phase de conception et d'implémentation.
Couche de Données pour Adobe Analytics, DTM, Launch et Tealium
Les couches de données peuvent avoir différentes structures. En général, nous distinguons celles qui viennent avec une structure basée sur les objets et une structure basée sur les tableaux.
Selon la définition de la couche de données par le World Wide Web Consortium (W3C), la syntaxe suit celle d'un objet JavaScript. Elle est officieusement raccourcie en CEDDL (Customer Experience Digital Data Layer).
Vous pouvez également y imbriquer d'autres objets ou tableaux :
window.digitalData = {pageName: "aperçu des sneakers",destinationPath: "/fr/sneakers",breadCrumbs: ["accueil","sneakers"],publishDate: "2020-07-01",language: "fr-FR"};
Adobe Analytics, Adobe Launch et Tealium suivent la structure CEDDL. Dans l'exemple ci-dessus, nous stockons les données dans un objet appelé digitalData. Le nom n'est pas standardisé et peut être choisi librement, mais vous devez déclarer le nom dans le système de gestion des balises.
Pour modifier les données, il existe plusieurs options (comme pour tout objet JS) cependant, la manière la plus simple est de simplement écraser les valeurs :
window.digitalData.language = "de-DE";
L'idée centrale de la structure basée sur les objets est qu'ils sont chargés une fois par chargement de page, mais ne sont pas beaucoup modifiés en fonction de l'interaction de l'utilisateur. Les données sont principalement statiques.
Le suivi des événements n'est pas déclenché par des événements qui entrent dans l'objet de la couche de données. Les événements sont suivis avec une bibliothèque de suivi distincte pour les envoyer à une plateforme d'analyse comme Adobe Analytics. Lorsque le code de suivi des événements est exécuté, l'objet de la couche de données est envoyé dans son intégralité et peut être utilisé lors de l'analyse des données.
//Événement avec couleur choisie_satellite.setVar("couleur des sneakers", "noir");_satellite.track("sélectionner couleur");
Utiliser Adobe Launch avec une couche de données basée sur des tableaux
Vous pouvez facilement utiliser Adobe Launch avec une structure basée sur des tableaux aussi. L'extension Adobe Launch Data Layer Manager le rend possible.
Voici quelques liens vers des ressources supplémentaires pour utiliser la version basée sur des tableaux avec Adobe Launch :
- Jim Gordon’s Démo de l'utilisation du Data Layer Manager avec Adobe Launch
- Data Layer Manager Extension avec documentation
Couche de données pour Google Tag Manager, Matomo et Piwik Pro
La couche de données pour Google Tag Manager, Matomo et Piwik Pro est basée sur des tableaux et est officieusement appelée la couche de données pilotée par les événements (EDDL).
Les données sont également gérées dans des objets, mais la structure globale de la couche de données GTM est un tableau avec des objets.
window.dataLayer = window.dataLayer || [{"pageCategory": "page de catégorie","pageName": "aperçu des sneakers","language": "fr-FR",}];
La logique de suivi avec une structure basée sur des tableaux est différente : Les nouvelles données ou les changements sont poussés dans la couche de données via dataLayer.push(). Ainsi, une insertion dans la couche de données peut déclencher l'exécution de balises dans le système de gestion des balises.
La différence fondamentale avec une structure basée sur des objets est que les changements sont généralement envoyés avec un événement et que les règles sont déclenchées en fonction de ces changements sans bibliothèque supplémentaire, simplement en observant si le tableau de la couche de données change.
Comme aucune autre bibliothèque comme _satellite n'est nécessaire, nous avons une dépendance en moins.
Une autre caractéristique de l'approche basée sur des tableaux est que les données changent assez fréquemment tout au long du parcours utilisateur, car toute interaction utilisateur peut modifier les variables de la couche de données.
Ainsi, une couche de données basée sur des tableaux est la base du suivi des événements et gère les données de manière plus flexible, tandis qu'une couche basée sur des objets sert plutôt de magasin de données statiques.
Grâce à cette flexibilité, une structure de couche de données basée sur des tableaux est considérée comme plus adaptée aux applications à page unique (SPA).
Cependant, vous pouvez également suivre les SPA avec une couche de données basée sur des objets, cela nécessitera simplement quelques lignes de code supplémentaires et potentiellement quelques cas particuliers à résoudre.
Si vous êtes au début d'un projet et avez le choix, je préférerais une couche de données basée sur des tableaux.
Changer une configuration existante d'une structure d'objet à un tableau est cependant inutile.
Systèmes de gestion de contenu avec couche de données incluse
Les utilisateurs de WordPress ont la tâche facile puisqu'ils peuvent utiliser ce plugin pour implémenter Google Tag Manager avec une couche de données préconfigurée.
Il se remplit automatiquement avec les catégories, les noms d'auteurs, les dates de publication et les termes de recherche.
Les points de données peuvent être cochés ou décochés dans les paramètres du plugin. De plus, le plugin propose des événements préconfigurés pour les soumissions de formulaires des plugins de formulaires les plus courants.
Si vous êtes propriétaire d'une boutique en ligne et utilisez WooCommerce pour WordPress, vous pouvez implémenter une couche de données e-commerce classique ainsi qu'une couche de données e-commerce améliorée avec le même plugin, ce qui est assez puissant.
Les utilisateurs de WordPress qui souhaitent utiliser Tealium peuvent utiliser un plugin pour Tealium.
Drupal a également un plugin.
Les utilisateurs de Wix et Squarespace peuvent implémenter Google Tag Manager via les outils de la plateforme mais doivent implémenter le code de la couche de données manuellement.
Implémentation de la couche de données
Alors, comment implémenter une couche de données ? - Puisque la planification et l'implémentation nécessitent des connaissances dans les domaines de l'analyse numérique, du développement frontend et du développement backend, l'implémentation est généralement réalisée par une agence web en collaboration avec un consultant en analytics.
Le consultant en analytics briefe l'agence web et dirige le projet jusqu'à ce que l'implémentation soit validée avec succès. Ensuite, le système de gestion des balises et les outils d'analytics sont configurés.
Si vous êtes intéressé et connaissez un peu de JavaScript, vous pouvez l'implémenter vous-même avec le guide d'implémentation suivant.
L'implémentation se déroule en 3 étapes :
1. Conception de la couche de données
La phase de conception consiste à définir quelles interactions doivent être mesurées ainsi que quelles dimensions.
Toutes les attributs du visiteur, de la session, de la page, du produit ou de l'événement peuvent être d'un intérêt potentiel lors de l'analyse des données et doivent être pris en compte pour l'architecture de la couche de données.
Pour décider quoi inclure, commencez par la fin en tête et demandez-vous quelles questions critiques pour l'entreprise doivent être abordées et concentrez-vous sur les points de données associés.
L'étape suivante consiste à déterminer comment ces points de données doivent être structurés et quelles dimensions sont les plus importantes à ajouter.
Exemple : Une école de langues utilisant un site WordPress en plusieurs langues souhaite connaître la langue maternelle de ses visiteurs et quelle langue étrangère les intéresse le plus. Le but est de potentiellement lancer des publicités en ligne via Facebook Ads ciblant des démographies avec des attributs similaires.
À l'étape suivante, nous devrons définir toutes les données pertinentes pour différents types de pages (page d'accueil, pages de cours, à propos, contact et actualités). Pour simplifier, concentrons-nous sur les pages les plus intéressantes et concentrons-nous sur la page d'accueil et les pages de cours.

Exemple : Couche de données Google Tag Manager basée sur des tableaux pour une école de langues
window.dataLayer = window.dataLayer || [{"language": "de", //Langue de l'interface utilisateur"sessionDuration": "182", //Durée de la session en sec"languageIntent": "es", //Langue du cours le plus visité"pageType": "page de cours","courseName": "Espagnol A1 - Débutant","courseLang": "es","courseLevel": "a1","courseDuration": "6" //Durée en semaines}];
Exemple : Couche de données basée sur des objets pour Adobe Launch
window.digitalData = window.digitalData || {"language": "de", //Langue de l'interface utilisateur"sessionDuration": 182, //Durée de la session en sec"languageIntent": "es", //Langue du cours le plus visité"pageType": "page de cours","courseName": "Espagnol A1 - Débutant","courseLang": "es","courseLevel": "a1","courseDuration": 6 //Durée en semaines};
2. Implémentation
Les couches de données doivent être implémentées sur chaque sous-page d'un site web. Les exemples de code ci-dessus montrent cependant l'état final calculé.
Lors de l'implémentation, les points de données doivent d'abord être sourcés pour être calculés dans leur état final, de sorte que la source réelle sera légèrement différente.
Pour donner un exemple réaliste, je suppose ce qui suit :
- La durée de la session et l'intérêt pour la langue sont collectés via un JavaScript personnalisé et stockés dans le stockage local du navigateur.
- La langue, le type de page et les données du cours peuvent être récupérés de la base de données via la réponse du serveur et mis à disposition sur les modèles de cours et la page d'accueil.
Le code source de la couche de données dans le backend selon les prémisses ci-dessus ressemblerait à ceci :
window.dataLayer = window.dataLayer || [{"language": <?php echo wpb_getpagedata("lang"); ?>,"sessionDuration": window.localStorage.sessionDuration,"languageIntent": window.localStorage.languageIntent"pageType": <?php echo wpb_getpagedata("type"); ?>,"courseName": <?php echo wpb_getcoursedata("name"); ?>,"courseSprache": <?php echo wpb_getcoursedata("lang"); ?>,"courseLevel": <?php echo wpb_getcoursedata("level"); ?>,"courseDuration": <?php echo wpb_getcoursedata("duration"); ?>,}];
Suivi des événements avec data layer push
Pour envoyer des événements à une couche de données GTM, vous pouvez utiliser sa méthode push et littéralement y pousser des événements.
window.dataLayer.push({"event": "réservation de cours","startWeek": "24"});
Le mot-clé event est un mot-clé spécial et peut être adressé comme un événement personnalisé à partir du conteneur GTM.
Le système de gestion des balises observe la couche de données et exécute une balise dès qu'un événement personnalisé prédéfini lui est envoyé.
Après qu'un événement est ajouté, le TMS peut par exemple envoyer un événement à Google Analytics.
Toutes les données pertinentes pour fournir le contexte (nom, langue, niveau de langue, durée du cours) sont disponibles et peuvent être envoyées avec l'événement, par exemple, la semaine de début du cours.
Dans une couche de données basée sur des objets, le même événement serait directement envoyé à Adobe Analytics via leur propre bibliothèque de suivi des événements.
Pour Adobe Launch, le code d'exemple serait le suivant :
_satellite.setVar("startWeek", 24);_satellite.track("réservation de cours");
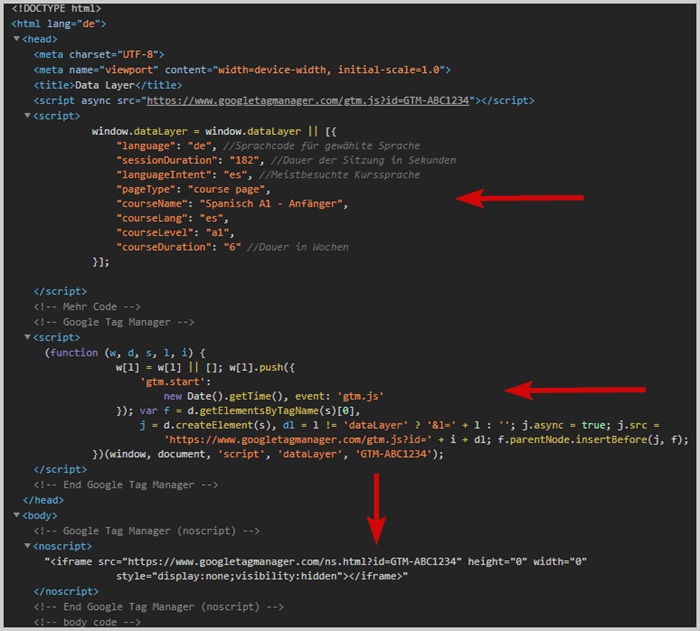
Positionnement du code dans le code source
Le code de la couche de données doit être ajouté dans le <head> de la page avant le système de gestion des balises.
En raison de cet ordre, vous vous assurez qu'il est déjà calculé lorsque le système de gestion des balises veut y accéder.
Exemple : Positionnement dans le code source
3. Débogage
Les procédures les plus courantes pour déboguer une couche de données consistent à simuler des chargements de page ou des événements pour vérifier que tous les points de données se remplissent avec les données correctes.
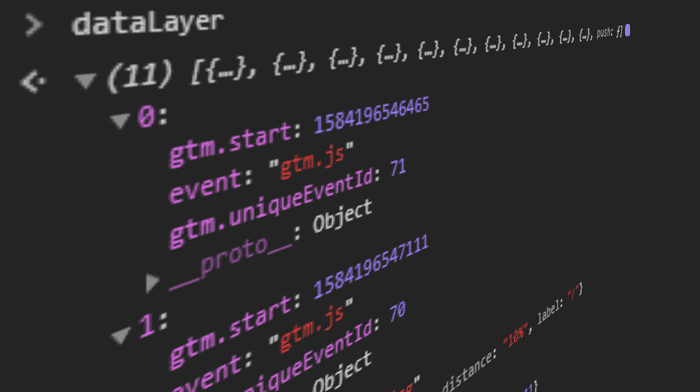
Comme elle est accessible globalement dans la console du navigateur, vous pouvez simplement imprimer toutes les valeurs dans la console (en supposant que des conventions de nommage standard sont appliquées) :
Sites web avec GTM
Object.assign(...dataLayer)
Sites web avec Adobe Launch ou DTM
digitalData
Tealium
utag.data ou utag_data
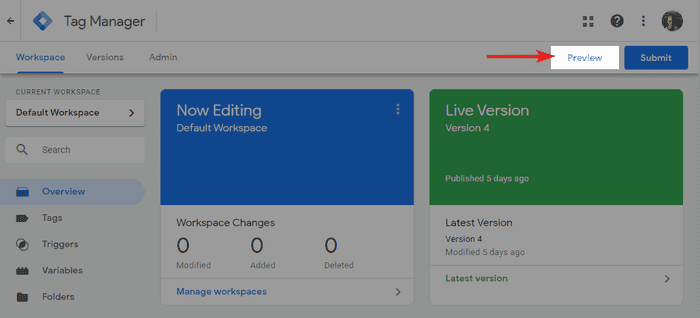
Google Tag Manager est même livré avec son propre mode Débogueur. Vous pouvez l'activer depuis l'interface GTM en cliquant sur aperçu en haut à droite.
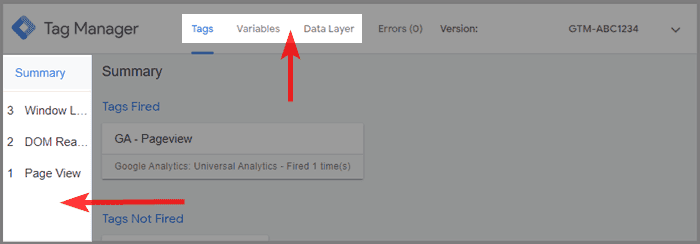
Si vous n'avez pas accès au conteneur de gestion des balises mais souhaitez quand même le déboguer, vous pouvez utiliser une extension Chrome.
Extensions Chrome pour la couche de données
Il existe une variété d'extensions potentielles pour le débogage. Je préfère celles qui prennent en charge la plupart des fournisseurs, afin de ne pas avoir à changer d'extension lors du débogage d'un autre site.
Les extensions Chrome suivantes sont actuellement mes préférées pour le débogage :
- Trackie - Extension basée sur Data Slayer et open source. Elle offre de bonnes performances et supporte GTM, DTM, Tealium et bien d'autres.
- Omnibug - Un autre tout-en-un avec support pour Adobe Analytics (DTM & Launch), ainsi que Matomo, GTM, Tealium et plus.
Extensions Chrome pour déboguer Google Analytics et GTM
- GTM/GA Debug - après activation de l'extension, un nouvel onglet sera disponible dans les outils de développement Chrome une fois ouverts (F12 sur Windows et CTRL+SHIFT+i sur Mac). Toutes les données pertinentes sont affichées dans une interface graphique et sont mises à jour pendant que vous naviguez sur un site web.
- Adswerve - dataLayer Inspector+ - enregistre tous les points de données pertinents dans la console du navigateur. Activez "conserver le journal" dans les paramètres de la console pour conserver les journaux lors de la navigation sur la page.
- Data Slayer - définitivement l'extension avec le nom et le logo les plus cools et mon ancien favori. Elle est open source avec une mise en page simple et fonctionne également avec Adobe DTM.
Décochez “utiliser la mise en page à trois colonnes là où c'est disponible”, “afficher les tags GA Classic” et “afficher les tags Floodlight” dans les paramètres de l'extension, sinon les journaux deviennent un peu désordonnés.
Extensions Chrome pour déboguer Adobe Analytics, Launch et DTM
- Launch & DTM Switch - vous permet de charger la bibliothèque de mise en scène ou de production du système de gestion des balises et peut activer le mode débogage.
- Debugger for Adobe Analytics - active le mode débogage. Alternativement, vous pouvez également taper
_satellite.setDebug(true)dans la console. - Adobe Experience Cloud Debugger - méta extension pour déboguer tous les produits Adobe.
- Adobe Experience Platform Debugger - successeur du débogueur Experience Cloud qui offre une meilleure vue d'ensemble (actuellement encore en version bêta).
- Tealium Data Layer Debugger - tableaux simples de toutes les valeurs actuelles.
Couche de données pour le commerce électronique
Les couches de données pour le commerce électronique sont plus étendues et leur structure est plus complexe. Elles doivent contenir plus de données et gérer plus d'événements.
C'est pourquoi la planification et l'implémentation d'un site de commerce électronique prennent considérablement plus de temps.
Le rapport de commerce électronique dans Google Analytics, par exemple, ne montre aucune donnée si l'implémentation ne suit pas leur documentation de la couche de données pour le commerce électronique.
Les grands magasins de commerce électronique nécessitent cependant des configurations de suivi encore plus avancées. Ils implémentent une couche de données pour le commerce électronique amélioré, ce qui permet encore plus de fonctionnalités dans Google Analytics.
Vous devez suivre strictement les lignes directrices d'implémentation pour Google Analytics pour que les rapports de commerce électronique fonctionnent. Cela concerne la structure de la couche de données et également les noms de variables.
Si vous choisissez une autre plateforme d'analyse pour le commerce électronique, vous êtes libre de planifier la structure comme vous le souhaitez.
Quand une couche de données n'est-elle pas nécessaire ?
Comme pour tout, il existe aussi des cas où l'effort supplémentaire d'implémentation d'une couche de données n'est pas justifié.
Dans les exemples ci-dessus, nous avons examiné des cas où nous avons extrait des données de différentes sources de données (Frontend, Backend, API) et résolu des problèmes qui se posent lorsqu'on travaille avec une variété de sources de données.
De nombreux sites web (appelés sites vitrine) n'ont cependant même pas de fonctionnalité de connexion ni de base de données.
Un autre facteur important est la fréquence des changements apportés au site web. De nombreux sites révisent rarement leur contenu ou ajoutent régulièrement des fonctionnalités. Je vois même des entreprises gérer des sites vitrine simples avec environ 50 sous-pages et un formulaire de contact comme la conversion la plus difficile.
Comme ces sites ne nécessitent probablement que des données provenant du frontend pour faire leur analyse de données, ils pourraient se contenter d'une configuration d'analyse simple sans couche de données. Cela ne rendrait pas la collecte de données beaucoup plus robuste ou plus sécurisée, ses avantages sont donc atténués. Dans de telles circonstances, les avantages ne justifient pas l'effort supplémentaire d'implémentation.
Les exemples typiques de moments où une couche de données n'est pas nécessaire sont les sites vitrine ou les sites de contenu avec un nombre limité ou presque aucune conversion difficile. En général, les propriétaires de tels sites souhaitent simplement catégoriser l'engagement des utilisateurs par leurs sections de contenu ou certaines classifications internes à l'entreprise.
De telles exigences peuvent être réalisées avec un peu de JavaScript avancé et un système bien pensé pour structurer le contenu.
Dès que la collecte de données à partir du frontend se casse régulièrement et définitivement lorsque une base de données doit être impliquée, une couche de données est recommandée.
Les solutions alternatives ne sont souvent que des solutions temporaires satisfaisantes, en raison des ambitions croissantes en matière d'analyse et de la collecte de données qui se casse régulièrement. De plus, toutes les solutions personnalisées sont généralement difficiles à transmettre à une autre agence.
Une couche de données a de bonnes chances de résister à l'épreuve du temps car elle est déjà un concept établi dans le secteur de l'analytique web, donc les agences web ont de plus en plus d'expérience dans l'implémentation et la maintenance de celle-ci.
Conclusion
Une couche de données est le standard d'or pour les configurations analytiques professionnelles. Elle améliore la qualité des données et, par conséquent, améliore l'analyse des données dans son ensemble, tout en répondant aux exigences de sécurité.
Pour les propriétaires de sites web ambitieux qui souhaitent commencer une analyse de données sérieuse, c'est la solution la plus simple et la plus robuste.
Si vous avez le choix, implémentez une structure basée sur des tableaux, car vous avez moins de dépendances et vous pouvez l'utiliser sur tous types de sites web.
Les sites de contenu, cependant, sont si limités en termes de fonctionnalité et apportent généralement un nombre limité de conversions importantes, qu'une couche de données peut potentiellement être négligée. Cela est particulièrement vrai si toutes les données nécessaires sont disponibles sur les pages ou pourraient être rendues disponibles par des détours.
Si vous voulez en implémenter une vous-même, le faire avec un site WordPress est probablement le plus facile. Cependant, toute exigence avancée ne vaut probablement pas le temps et le risque de résultats insatisfaisants.
Par conséquent, l'implémentation avec l'aide d'un consultant en analytics est généralement la voie à suivre, car elle permet de gagner du temps et d'éviter des risques inutiles.
Je vous recommande d'installer l'une des extensions Chrome mentionnées pour inspecter les couches de données de certains grands sites web. C'est généralement une grande source d'inspiration et fournit des indicateurs clés de performance intéressants à potentiellement intégrer dans vos propres configurations analytiques 😉.
Documentation des couches de données des différents fournisseurs de TMS
- Google Tag Manager: Initialisation et modification des données
- Adobe Launch: Initialisation
- Tealium iQ: Initialisation et modification des données
- Matomo: Initialisation et modification des données
- Piwik Pro: Initialisation et modification des données
FAQ
Qu'est-ce qu'un exemple de couche de données ?
Un exemple de couche de données est fourni dans l'article. Un objet JavaScript stocke les données d'un site web, d'une base de données ou d'une source externe de manière centrale, flexible et facilement accessible. Un exemple de code pour initier une couche de données pour Google Tag Manager est : window.dataLayer = window.dataLayer || [{ "pageCategory": "page de catégorie", "pageName": "aperçu des sneakers", "language": "fr-FR",}];
Quelles sont les variables de la couche de données ?
Les variables de la couche de données sont des paires clé-valeur au sein de la couche de données qui stockent des informations spécifiques. Ces variables peuvent inclure les caractéristiques de la page, les données de comportement des utilisateurs, et plus encore, servant de référentiel central de données pour l'analyse et le suivi.
Pourquoi utiliser une couche de données ?
Une couche de données est essentielle pour une collecte de données robuste, flexible et sécurisée. Elle centralise les données provenant de diverses sources, les rendant facilement accessibles et cohérentes sur différentes pages web et interactions utilisateur. Cette approche améliore la qualité et la fiabilité des données, ce qui est crucial pour la prise de décisions basées sur les données.
Ai-je besoin d'une couche de données ?
Bien qu'elle ne soit pas toujours nécessaire, une couche de données est généralement conseillée pour ceux qui prennent leurs ambitions d'analyse de données au sérieux. Elle offre une qualité de données, une fiabilité et des économies de temps à long terme qui justifient les efforts d'implémentation plus élevés.
Quels sont les avantages d'une couche de données ?
Les avantages d'une couche de données incluent : La disponibilité des données qu'elles soient visibles sur la page ou non. Une collecte de données robuste. La réduction de la perte de données pour les requêtes de données asynchrones. Une collecte de données sécurisée à partir de multiples sources.
Tous les sites web ont-ils une couche de données ?
Tous les sites web n'ont pas une couche de données. Son implémentation dépend de la complexité du site et de la profondeur de l'analyse des données requise. Les sites simples peuvent ne pas avoir de couche de données, tandis que les sites plus complexes, en particulier ceux axés sur la prise de décisions basées sur les données, en auront probablement une.
Comment accéder à la couche de données ?
La couche de données est accessible globalement dans la console du navigateur. Pour les sites avec Google Tag Manager, vous pouvez y accéder en utilisant dataLayer ou Object.assign(...dataLayer). Pour Adobe Launch ou DTM, vous pouvez y accéder en utilisant digitalData.
Comment ajouter des données à la couche de données ?
Pour ajouter des données à la couche de données, vous utilisez la méthode dataLayer.push(). Par exemple : window.dataLayer.push({ "event": "réservation de cours", "startWeek": "24" }); Cette méthode est utilisée pour ajouter de nouvelles données ou des modifications à la couche de données. La clé event peut être utilisée pour déclencher une autre exécution de balise dans le système de gestion des balises.
Ressources supplémentaires
- Simo Ahava à propos de la couche de données dans GTM et comment gérer les données dans celle-ci.
- Lisez mon tutoriel sur Google Tag Manager et apprenez à le configurer.
- La présentation de Kevin Haag à Measurecamp Berlin 2019 sur la couche de données pilotée par les événements dans Adobe Analytics